I wanted a reason to practice my python skills, and so I've tried to make my own RLE compression thingy for the SNES.
The way the format works is like this. Say you have these bytes:
The new file is made up of pairs of two: one byte for how many of the second byte should be copied.
An FF is appended at the end to mark where the routine should stop copying, so the output would be:
The .py file does this perfectly:
The problem is the routine to copy the bytes to vram:
It's called like this:
Now, this is the expected output:
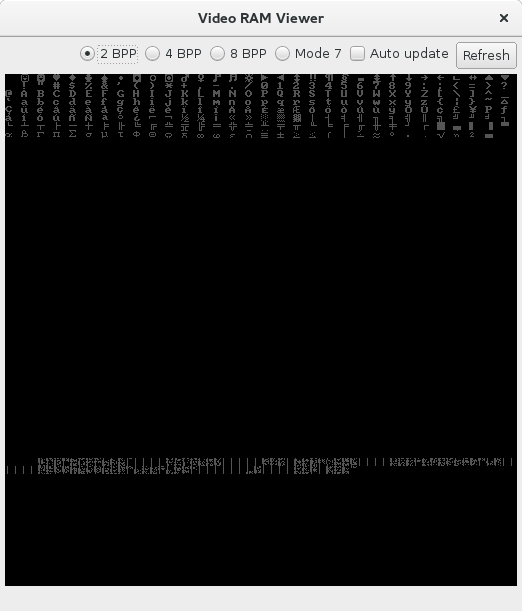
And this is the actual output:
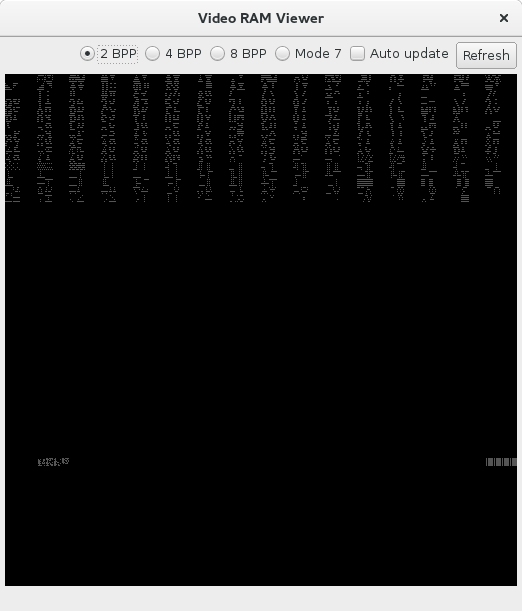
I'll give more info on my code if need be, but can anyone see anything wrong that might cause an error in things being copied over?
The way the format works is like this. Say you have these bytes:
Code:
00 ff 00 00 ff ff 00 00 00 00 00 00 ff ff ff ff ff ff
The new file is made up of pairs of two: one byte for how many of the second byte should be copied.
An FF is appended at the end to mark where the routine should stop copying, so the output would be:
Code:
01 00 01 ff 02 00 02 ff 06 00 06 ff ff
The .py file does this perfectly:
Code:
#!/usr/bin/env python3
# basic rle compression program
# by nicklausw
# this format works as follows.
# one byte is read, and that is
# how many of the next byte to copy over. repeat.
# when the first byte is $ff, the copy is done.
import sys
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("in_file", help="the chr data to be rle'd")
parser.add_argument("out_file", help="the rle'd output")
args = parser.parse_args()
f_in = open(args.in_file, 'rb')
f_out = open(args.out_file, 'wb')
# python doesn't need variable initialization i think,
# but for clarity's sake.
byte_n = 0 # byte
byte_c = 1 # byte count
for c in f_in.read():
if c != byte_n or byte_c == 0xFE:
f_out.write(bytes([byte_c]))
f_out.write(bytes([byte_n]))
byte_c = 1
byte_n = c
else:
byte_c += 1
# now catch the last time around
f_out.write(bytes([byte_c]))
f_out.write(bytes([byte_n]))
# the end mark
f_out.write(bytes([0xFF]))
f_in.close()
f_out.close()
# basic rle compression program
# by nicklausw
# this format works as follows.
# one byte is read, and that is
# how many of the next byte to copy over. repeat.
# when the first byte is $ff, the copy is done.
import sys
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("in_file", help="the chr data to be rle'd")
parser.add_argument("out_file", help="the rle'd output")
args = parser.parse_args()
f_in = open(args.in_file, 'rb')
f_out = open(args.out_file, 'wb')
# python doesn't need variable initialization i think,
# but for clarity's sake.
byte_n = 0 # byte
byte_c = 1 # byte count
for c in f_in.read():
if c != byte_n or byte_c == 0xFE:
f_out.write(bytes([byte_c]))
f_out.write(bytes([byte_n]))
byte_c = 1
byte_n = c
else:
byte_c += 1
# now catch the last time around
f_out.write(bytes([byte_c]))
f_out.write(bytes([byte_n]))
# the end mark
f_out.write(bytes([0xFF]))
f_in.close()
f_out.close()
The problem is the routine to copy the bytes to vram:
Code:
.proc rle_copy_ppu
setxy16
seta8
ldy #$00
loop:
seta8
lda (rle_cp_ram), y
cpa #$ff
beq done
seta16
and #$ff
tax
iny
seta8
lda (rle_cp_ram),y
jsr rle_loop
iny
jmp loop
done:
rts
rle_loop:
seta16
;and #$ff
loop2:
sta PPUDATA
dex
bne loop2
rts
.endproc
setxy16
seta8
ldy #$00
loop:
seta8
lda (rle_cp_ram), y
cpa #$ff
beq done
seta16
and #$ff
tax
iny
seta8
lda (rle_cp_ram),y
jsr rle_loop
iny
jmp loop
done:
rts
rle_loop:
seta16
;and #$ff
loop2:
sta PPUDATA
dex
bne loop2
rts
.endproc
It's called like this:
Code:
; copy font
setaxy16
stz PPUADDR ; we will start video memory at $0000
lda #font
sta rle_cp_ram
jsr rle_copy_ppu
setaxy16
stz PPUADDR ; we will start video memory at $0000
lda #font
sta rle_cp_ram
jsr rle_copy_ppu
Now, this is the expected output:
And this is the actual output:
I'll give more info on my code if need be, but can anyone see anything wrong that might cause an error in things being copied over?