I think it is a good idea to make a Bad Apple demo for the SNES, to compete with the Genesis demo.
If the SNES demo video runs at 30fps fullscreen 2bpp, then it would take 7kB of DMA per frame. Since we do not need to use the OAM for this demo, we can DMA up to 6kB of data per frame. In order to fit 7kB of graphical patterns into 6kB, we can take advantage of solid colored tiles that are all black or all white.
I could program the dma loading scheme and pack-to-planar conversion, but I don't know how to do the video encoding part.
Why not.
I don't think a runtime packed-to-planar conversion is needed, though. Pretty much everything could be done in preprocessing.
A thing that may work on the SNES is interleaved bitplane updates. Like, one frame (1/60) we update bit 0, other frame bit 1. Will create some kind of motion blur, but may be acceptable. This will cut VRAM bandwidth, and the whole (bitplane of) the frame buffer could be DMAed, without breaking it into sequence of DMAs; tile update could be done in a RAM buffer.
I
reverse engineered how the 15fps version of Bad Apple for NES encodes video. The screen is divided into a grid of 16x30 blocks of 4x2 texels (2 tiles, 16x8 pixels). There are a handful of frames, mostly before the lyrics begin, that use a special code for "all blocks modified" (I-frame, also called keyframe) or "no blocks modified" (D-frame), but the vast majority of frames in Bad Apple are P-frames. Each P-frame has 4 bytes for which rows of tiles have at least one modified row, then 2 bytes for which blocks are modified, then 1 byte for each modified block.
What you're talking about doing is making all frames I-frames and using a bitwise encoding to store which tiles in a frame are black, which are white, and which have a pattern. Then you'd send the nametable and unique patterns for each frame. I could write prototype code in Python and 6502 for that; you could optimize it for native mode.
Would it be acceptable to use mosaic mode for 128x112 texels? That'd let you use H-flipped tiles, V-flipped tiles, and VH-flipped tiles to fit the entire display into 3.5 KiB per frame, at the cost of some chunkiness.
Or would it be acceptable to use 1bpp, with even tile columns using black, white, black, white, and odd tile columns using black, black, white, white? That'd cut it down to 7 KiB per frame, which fits in 6+1.
One thing I'd like to see where it freezes on the apple as Marisa is grabbing it is this:

Then I wonder if the dropping cup that shatters could be changed into a dropping iPhone that shatters.
I want it to be the same quality as the Genesis version, and using a smaller resolution would look bad in comparison.
A possible compression technique can be to do RLE on 8x1 slivers, with the tiles arranged vertically.
RLE is certainly not something well suitable for video, even a silhouette one.
It needs interframe compression, i.e. storing only difference between frames, with a fixed dictionary of often used elements (solid black and solid white at the least), maybe with loss of details (replacing tiles with similar entries of the dictionary set), maybe with Huffman or LZ on top of all this.
The trolls will still claim superiority because the Genesis ROM runs in 320-pixel mode. One might have to use hires to beat that. Fortunately, FFmpeg has no problem scaling a 480x360 video to 512x224.
At this scale, I don't see how interframe compression would help much. Just about every non-solid tile would change each frame.
In any case, some sort of compression into an average of about 1280 bytes per frame would be needed to fit the thing into 8 MB. (At which point one of them is likely to haul out the Sega CD with every Touhou fan video known to man encoded in Cinepak.)
I took an equally spaced sample (one every 30 frames) and counted how many 8x8 pixel tiles were all black or all white. This is
the key metric for figuring out how to fit everything in 12 KiB/frame of video memory bandwidth.
- 512x224: 355099 of 394240 solid (90.07%)
- 256x224: 171397 of 197120 solid (86.95%)
Have you tried disassembling the Genesis version to see how it manages 15:1 compression? I'm pretty sure it'll take more than just solid tile elimination. Perhaps there's some advantage to packed pixels.
But when watching a YouTube video of the Genesis version, I did notice a bunch of gray artifacts along certain near-horizontal edges. Perhaps this could be exploited to use one of four formats for each tile: solid black, solid white, 1bpp, or 2bpp.
There might also be a win in using RLE for runs of solid tiles. My sample showed that most solid tiles were after another solid tile.
- 512x224: 355099 of 394240 solid (90.07%), 340911 solid after solid (86.47% of total)
- 256x224: 171397 of 197120 solid (86.95%), 158682 solid after solid (80.50% of total)
Another cheat is to use fake widescreen. Encode only 168 pixels tall, keep tile rows outside this range black, then do some subtle horizontal scrolling over the affected area. This makes things look somewhat more cinematic, even if the trolls might call you out on reduced res.
I wonder how much of the video can be decomposed into areas where just two horizontal pixel runs differ from the background color. That might allow drawing much of the video with window registers.
And about the music: BRR (4.5 bits/sample) at 12 kHz mono for 220 seconds would take 1485000 bytes. I wonder to what extent the BRR data itself could be compressed.
Quote:
I wonder to what extent the BRR data itself could be compressed.
Trust me, very poorly.
I have tested this. Even very advanced compressions such as BZIP2 will not compress anything when compressing BRR data.
The only thing you could possibly do is separate the BRR header data from the other data and compress the header efficiently, but even then you'll never compress more than 1/9 of the whole data which is very poor.
Shiru wrote:
RLE is certainly not something well suitable for video, even a silhouette one.
It needs interframe compression, i.e. storing only difference between frames, with a fixed dictionary of often used elements (solid black and solid white at the least), maybe with loss of details (replacing tiles with similar entries of the dictionary set), maybe with Huffman or LZ on top of all this.
How do you store the differences between frames? Use motion vectors on tiles, and overlay a compressed tile over it?
First what you need to do is see how the players for Bad Apple (Genesis) and the intro for Sonic 3D Blast work.
I'm not so sure you need motion compensation in the first place. Let's first figure out how to code keyframes efficiently. For example, I figured out how to encode tiles on the left or right edge of a silhouette at one-half bit per pixel. Each byte represents two rows, with nibbles taken from the following table:
Code:
.byte $00, $80, $C0, $E0, $F0, $F8, $FC, $FE, $FF, $7F, $3F, $1F, $0F, $07, $03, $01
This allows efficient coding of edge tiles:
Code:
0: . . . . . . . .
1: []. . . . . . .
2: [][]. . . . . .
3: [][][]. . . . .
4: [][][][]. . . .
5: [][][][][]. . .
6: [][][][][][]. .
7: [][][][][][][].
8: [][][][][][][][]
9: . [][][][][][][]
A: . . [][][][][][]
B: . . . [][][][][]
C: . . . . [][][][]
D: . . . . . [][][]
E: . . . . . . [][]
F: . . . . . . . []
More detailed edge tiles will likely need another method.
Or use "vector quantization", in which a representative set of a few tens of thousands of tiles are reused to form images.
Okay, here is a simple algorithm to start with. Obviously it's not going to be the final algorithm, but it's a starting place.
mmrrrrrr
m: mode
00: solid black tile
01: solid white tile
10: 1 bpp tile
11: 2 bpp tile
r: run legnth (1-64)
BTW, aren't tiles in hi-res mode always 16 pixels across?
Motion vectors is kind of overkill. Just check which tiles are changed (with amount threshold optionally) between frames, store them somehow efficiently enough, put the new tiles over previously decoded frame.
A dictionary I was talking about could contain not only solid colors, but also some common blocks, or blocks that could replace a number of similar looking blocks (this reduces quality, but saves room). Like, almost solid tile without few corner pixels, etc. Staticstics of common blocks could be collected from source frames before compression.
If it can help, here are the sources of the genesis version :
https://dl.dropboxusercontent.com/u/933 ... ple_src.7zBasically it does frame difference and only store tilemap and modified tiles, it mainly uses dictionaries to encode redundant tile data but there are severals compression schemes. I spent many time in building the video encoder but still it is not very efficient...
I used a tool to generate the dictionary tile unpack code, that explain why some part look weird and badly optimized (as some move.l #0x00000000, %d0 sequences).
I would really like to see what the SNES could do here but i am pessimist about the decompression part. It eats a lot of time on the 68000 and i don't see how the 65816 can compete here. Maybe by using simpler compression schemes but it would not fit in 8 MB then...
Still the MD offers some advantages as linear packed tile data and no bank stuff to deal with.
The SNES offer the native 2BPP mode that MD does not have but can be easily simulated using palette trick.
Good luck with your project, i really wish to see something coming from that

Bumping because I was away for almost a month.
First of all, let's remember there are multiple Bad Apple demos on the Mega Drive, OK? I don't know how MtChocolate's works, Stef released the source code to his, and then there's
this which in my opinion is the best so far and the method is explained in that thread too (albeit no source code). The only glitches I noticed in the latter seemed to be more encoding bugs than actual limitations.
Also not sure how the 65816 competes in decompression, given that's something that usually works with small numbers so it shouldn't be at much of a disadvantage compared with the 68000. Register usage would be the biggest problem, in my opinion, and that depends a lot on the coder's skill.
By the way, at this rate we'll find a way to put videos on floppy disks =P
I've been busy celebrating Christmas with family so I had limited time programming.
I think I'll use the method you posted since it's the simplest. I would need somebody to post a ROM with all the video data, because I don't know how to convert a video file.
Sik wrote:
Bumping because I was away for almost a month.
First of all, let's remember there are multiple Bad Apple demos on the Mega Drive, OK? I don't know how MtChocolate's works, Stef released the source code to his, and then there's
this which in my opinion is the best so far and the method is explained in that thread too (albeit no source code). The only glitches I noticed in the latter seemed to be more encoding bugs than actual limitations.
Also not sure how the 65816 competes in decompression, given that's something that usually works with small numbers so it shouldn't be at much of a disadvantage compared with the 68000. Register usage would be the biggest problem, in my opinion, and that depends a lot on the coder's skill.
By the way, at this rate we'll find a way to put videos on floppy disks =P
The version you are talking about is very interesting, first because it fits in 4MB (which is a big advantage to test on regular MD flash cart) and also because it is probably a far better candidate to port on SNES. The compression scheme is far lighter than my version (it does not even use the DMA) and can probably be ported to the SNES cpu without much troubles.
The drawback of this version is the blocky stuff you call glitches, they are due to the compression as you can't fit the whole video (and sound) in 4MB without loss (especially on such limited hardwares).
My 8 MB version is lossless for the video and that is quite an achievement (i believe), i initially had a 4MB lossless version (without sound) but i was not able to unpack it fast enough (between 10 and 30 FPS) so i had to use a simpler codec (i ended with 6.6 MB of video and 1.3 MB of sound).
The problem with the 65816 about decompression is not only the number of register but also the "fillrate" capabilities, still i guess a skilled coder could do some nice things with it
Stef wrote:
The drawback of this version is the blocky stuff you call glitches, they are due to the compression as you can't fit the whole video (and sound) in 4MB without loss (especially on such limited hardwares).
No, they were actual glitches. For example, there's one point where the broom appears horizontally across the screen, there's one tile that appears like solid gray even though a tile that was half white half black would have been much better (heck, repeating one of the surrounding tiles would have done the job). Why the encoder chose not to do that is beyond me.
I had worked on doing Bad Apple demo as well, but for PCE. The SNES shares a similar advantage, native 2bpp tile format. Less bandwidth to transfer. But since the pixel format is planar, the compression has to be tailored as such. My approach was to use was to use a number of binary tree sets, for the compression encoding. My target size was also smaller than both MD and SNES (2.5megabytes total).
Here's the idea I had:

I preprocessed all frames into 3 shades; black, grey, and white. While I had technically 4 shades to work with (2bpp), 3 colors compressed much better than 4. I also separate the image into two 1bpp images. The decoder follows a variable length operation system; binary encoded. Each frame is checked for statistics, to prioritize encoding to produce the smallest length for the highest occurring instance of that operation - per frame. I encode the picture into vertical 8pixel wide strips. A simple RLE system works for long runs of vertical rows. If the rows are tiles, RLE groups of tiles. If the tile only has few sets of RLE, then a bitmask+constant compression method is used (0=fetch literal, 1=use constant). The tile rows can also be further compressed if you represent rows of pixels are left or right shifts, of the proceeding rows. These would be padded shifts (similar to a (sec, rol/ror) or (clc,rol/ror) <n> number of times). This last part really helped bring the number down, per pic. There were other optimizations, where parts of the 3 color image that only used black or white, only needed 1bpp plane. So unless the specific tile had grey parts, it was 1bpp.
Another layer of compression sits on top; 1bit mask for all 8x8 tiles (0=reuse old tile, 1= build new tile). This helps keep the vram bandwidth down (and keep the cpu from building redundant tiles). And then finally, some sort of temporal tile/tilemap compression (for statics parts over frames).
Anyway, that's what I came up with. I never finished it though. I hadn't got to the audio compression side yet. I wanted to see what cpu resource was left over, before tackling that.
Sik wrote:
No, they were actual glitches. For example, there's one point where the broom appears horizontally across the screen, there's one tile that appears like solid gray even though a tile that was half white half black would have been much better (heck, repeating one of the surrounding tiles would have done the job). Why the encoder chose not to do that is beyond me.
Oh ok, i did not noticed it really... improving the encoder could probably help but i remember i had some hard time in trying to figure a good algorithm to compare 2 tiles and find "closest" one (simple sum intensity delta or stuff like that does not work that well). But I guess there is some already nice solutions existing for that in conventional codec. Glad i was able to use a lossless codec for my version.
tomaitheous> Any chance you get back to it ?
The sound compression is not a big deal, it's really not significant compared to the video itself !
I had so much on my mind I forgot about this. I got done with the tile map decompression, now I have to decompress the tiles themselves. This frame takes up 120 tiles, and the tile map is compressed to 137 bytes.
I realize that it is disappointing that I only have a single frame finished. I just want to have a working compression format first before worrying about programming a video encoder.
psycopathicteen: You were working on a shadow art video player for Super NES, and you
got stuck on the compressor. What's the compressed format supposed to look like? Perhaps I can bang something out in Python.
I just looked through my old code. The format is this:
first comes the tile map of the frame:
00LLLLLL = L amount of white tiles
01LLLLLL = L amount of black tiles
1xLLLLLL = L amount of pattern tiles
It knows when to stop, when it hits the bottom of the screen. Then directly after that is the tile pattern table:
Word 0: One bit for each 8x1 sliver, for next 2 tiles. 0 = repeat last 8x1 sliver, 1 = new 8x1 sliver.
Word 1: 8x1 slivers themselves, with repeated slivers removed
Then when 2 tiles have been processed, it repeats, until it has as many tiles as there are "pattern tiles" in the frame.
Then it repeats for the next frame.
psycopathicteen wrote:
first comes the tile map of the frame:
00LLLLLL = L amount of white tiles
01LLLLLL = L amount of black tiles
1xLLLLLL = L amount of pattern tiles
These are in left to right, top to bottom order, in a 32x28 array, correct? And I assume "x" either is always 0 or is ignored. And does L=0 produce zero or one of a tile?
Quote:
Then directly after that is the tile pattern table:
Word 0: One bit for each 8x1 sliver, for next 2 tiles. 0 = repeat last 8x1 sliver, 1 = new 8x1 sliver.
Word 1: 8x1 slivers themselves, with repeated slivers removed
What do you mean by "word", and what's this "next 2 tiles"?
Otherwise, this sounds very similar to the
PB53 format that Action 53 and RHDE use. If you can change your code to decode PB53, or you just pinch the PB53 decoder from the
src folder of the
RHDE source code and adapt it to produce the Game Boy tile format that Super NES 2bpp planes use, then you already have a compressor for the pattern table part in the
tools folder.
I really want to make Super Bad Apple work. If you can provide some test vectors of decompressed and compressed tile data, I might have something for you by Monday.
psycopathicteen wrote:
I did notice that it can be compressed a lot, just by doing RLE on 8x1 slivers in a vertical direction.
What's the target size for this? Do you want to max out the address space, or go for Super Everdrive compatibility?
How fast can a single HDMA channel feed the APU? Is it reasonable to give it two or three bytes every scanline? If so, would the SPC700 have enough time left to do other stuff? Time-critical stuff? I have a few schemes in mind, depending on how much space is left for audio...
Quote:
I really want to make Super Bad Apple work. If you can provide some test vectors of decompressed and compressed tile data, I might have something for you by Monday.
What are test vectors? Should I post an example of a compressed data?
Let's say you want to draw a screen that has a 16 rows of white tiles, followed by 8 rows of black tiles, followed by 4 rows of vertically striped tiles, with the stripes inversed every other row.
It should be like this:
Code:
db $3f,$3f,$3f,$3f,$3f,$3f,$3f,$3f //8 sets of 64 white tiles
db $7f,$7f,$7f,$7f //4 sets of 64 black tiles
db $bf,$bf //2 sets of 64 pattern tiles
//32x28 tile map is finished, now the pattern table data
dw $0001 //first 8x1 sliver is a new sliver, followed by 15 copies of it. This should render 2 striped tiles, side by side.
dw $aaaa //first 8x1 sliver, 2bpp planar format
dw $0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000
// continue using that 8x1 sliver, for 15 more tile pairs
dw $0001 //first 8x1 sliver is a new sliver, followed by 15 copies of it. This should render 2 striped tiles, side by side.
dw $5555 //first 8x1 sliver, 2bpp planar format
dw $0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000
// continue using that 8x1 sliver, for 15 more tile pairs
dw $0001 //first 8x1 sliver is a new sliver, followed by 15 copies of it. This should render 2 striped tiles, side by side.
dw $aaaa //first 8x1 sliver, 2bpp planar format
dw $0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000
// continue using that 8x1 sliver, for 15 more tile pairs
dw $0001 //first 8x1 sliver is a new sliver, followed by 15 copies of it. This should render 2 striped tiles, side by side.
dw $5555 //first 8x1 sliver, 2bpp planar format
dw $0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000
// continue using that 8x1 sliver, for 15 more tile pairs
// pattern table is finished
psycopathicteen wrote:
Quote:
If you can provide some test vectors of decompressed and compressed tile data, I might have something for you by Monday.
What are test vectors? Should I post an example of a compressed data?
. And thank you.
Quote:
Let's say you want to draw a screen that has a 16 rows of white tiles, followed by 8 rows of black tiles, followed by 4 rows of vertically striped tiles, with the stripes inversed every other row.
It should be like this:
Code:
db $3f,$3f,$3f,$3f,$3f,$3f,$3f,$3f //8 sets of 64 white tiles
db $7f,$7f,$7f,$7f //4 sets of 64 black tiles
db $bf,$bf //2 sets of 64 pattern tiles
This confirms three assumptions: n+1, $C0-$FF is invalid, and we aren't trying to assign duplicate pattern tiles.
Quote:
Code:
dw $0001 //first 8x1 sliver is a new sliver, followed by 15 copies of it. This should render 2 striped tiles, side by side.
Fourth assumption confirmed: Topmost bit of a sliver lies in the lowest bit of a tile pair. But can bit 0 of the first tile on a screen ever be 0, where the first sliver in a pair of tiles is not a new sliver? And what happens to the pattern table when the nametable contains an odd number of pattern tiles?
Quote:
Code:
dw $aaaa //first 8x1 sliver, 2bpp planar format
dw $0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000,$0000
// continue using that 8x1 sliver, for 15 more tile pairs
Yet another assumption confirmed: A sliver can continue from one tile pair to the next.
I can also make the tool to convert "Bad Apple.mp4" directly to this format, reading frames out of FFmpeg, and provide a couple seconds of encoded video for you to test your decoder with.
If there is an odd number of tiles, it will add a dummy tile.
Thanks. Now I'll work on encoding one frame.
Attachment:
 sba_nofront.png [ 1.17 KiB | Viewed 2551 times ]
sba_nofront.png [ 1.17 KiB | Viewed 2551 times ]
And one more thing: Is white color 3 and black color 0, or vice versa?
Try putting sba_nofront.sba into your decoder and seeing if you get anything remotely recognizable. I made sbadec.py based on your worked example, getting it to render as you described. Then I made sbaenc.py to fit the format, and sbadec.py correctly decoded it on the first try.
I piped the Bad Apple video into this codec, and I count 6472 frames totaling 8439264 bytes, an average of 1304 bytes per frame.
(Not this Bad Apple.)
How many unique tiles do you have in there?
In 6472 frames:
780856 total tiles that aren't white or black
738482 total tiles if intra-frame duplicates are removed
357319 total tiles if cross-frame duplicates are removed
The largest frame is #2809 with 394 tiles that aren't completely black or white.
You know, all this compression stuff is way over my head, but have you tried using hi-res mode? I know BG2 is 2bpp, but I don't know if you'd be able to update in time. (Just curious, but do you know If the widow layer then operates in 512-448, or does it still use 256-224 like sprites?)
Oh yeah, about updating all the tiles in time, what frame rate is this supposed to run at?
Oh, and another thing, are you using different shades of gray to smoothen out edges, or would this mess with the compression method and potentially add more tiles to update? (Edit: never mind. If you sample picture is correct, you are.)
Unless there's some HD version I missed, the original video is only 320x240 pixels. Hi-res wouldn't help much.
So the original drawing was 320x240? Also, what system even runs using that? (I know the Irem m92 arcade board does, but it obviously wasn't using that.

) I know the Genesis runs at 320x224, unless you can also have it at 320x240 To make up for the resolution loss, what have you been doing? cropping the image to be 256x224 or resizing it? The sample picture seemed to be slightly taller than wide, (to make up for the 7x8 aspect ratio) which leads me to believe it is being resized.
Espozo wrote:
So the original drawing was 320x240? Also, what system even runs using that?
PC. Underscanned 320x240 was the native resolution of Mode X, and it is still the native resolution of 240p video on the Internet. Overscanned 240p is the native resolution of TV, and with square pixels, that's 320x240.
Quote:
make up for the resolution loss, what have you been doing? cropping the image to be 256x224 or resizing it? The sample picture seemed to be slightly taller than wide, (to make up for the 7x8 aspect ratio) which leads me to believe it is being resized.
Currently I'm just resizing to 256x224. If the video was framed for overscan, with safe areas around important figures, I would have resized to 280x240 and cropped to 256x224. But my guess is that it's framed for the underscan environment of Niconico and YouTube. Once I hear back from psycopathicteen about whether my sample frame decodes correctly, I'll post my full transcoder that wraps avconv.
Are you planning to modify the video with the
anti-Apple stuff, or would that be a separate version? I'm thinking it would be better if the main version were simply as exact a duplicate of the original as possible.
The version I'm working from currently is an exact copy without any of the anti-Apple stuff. Once we get the canonical version close to working, then I'll figure out how to sub in the logo and the iPhone.
tepples wrote:
Unless there's some HD version I missed, the original video is only 320x240 pixels. Hi-res wouldn't help much.
Well, there's
this
Isn't that just upsampled?
...from 512x384? What the hey?
The original version is
here. (It seems to require an account to view the video, though you can get around that with a bit of help from Google.) The standard resolution for videos there is 512x384, or at least it was back in 2009 when the video was uploaded.
I've got a copy of it I downloaded from there a while ago. Maybe I should download it again and see if there's a newer encode.
Well, I was bored so I made tepples picture with the apple logo with the x thing through it 512x448.
Attachment:
 Bad Apple hi-res shade.png [ 2.53 KiB | Viewed 2402 times ]
Bad Apple hi-res shade.png [ 2.53 KiB | Viewed 2402 times ]
If you want to know how I did it, I manually drew it so it's not that practical...
And, sorry, but what even is bad apple? I thought it was originally some sort of tech demo for the Genesis, but it was originally some sort of Japanese music video? Even though I'm not into anime or whatever, I think the picture is far better than the actual song, partially because I don't understand what they are saying and the English subtitles I saw for it really didn't translate from Japanese well, like if you tried to make an English rap Spanish, it wouldn't rhyme, and I'm not a big fan of the high-pitched feminine voice that seems to be popular over there. Also, was this made by Toho, who made Godzilla?
Oh yeah, and has anyone ever even thought about using different palettes for areas where there is a large transition from black to white? I saw the video, and I think it would make things like the biggest frame picture look better, even if it would be more complicated to make. I'm thinking you could make something similar to what the dforce guy made for super road blaster, except 2bpp.
Toho and
Touhou are unrelated, despite being pronounced the same.
Touhou Project is a series of freeware bullet-hell cute-em-up games for PC developed by Team Shanghai Alice. (See articles in
Wikipedia,
Cracked, and
All The Tropes.) Fans of the games made a shadow art music video featuring characters from the games on top of a cover version of "Bad Apple", a song from the soundtrack of
Lotus Land Story, one of the games in the series. And among developers of video codecs for retro consoles, this fan-made video for "Bad Apple" has become the standard test footage for demonstrating codecs designed for shadow art.
And I originally drew the "Apple logo with enclosing circle backslash" in 640x480 before scaling it to 280x240 and cropping it to 256x224.
Now as for technical aspects, the video is still highly compressible, possibly because individual slivers aren't packed in any way.
Okay, so it nearly fits in 8 MB, assuming you've encoded it correctly, and could in principle fit in less than 4 MB if the S-CPU were arbitrarily powerful and had unlimited RAM. I wonder if it's possible to squish it much more with the available resources...
Even as it stands, there's enough room in a 95 Mbit map for 32 kHz mono or 16 kHz stereo in BRR format, with enough left over that the latter could be augmented with high-frequency samples (the sounds that show up in the top octave aren't especially diverse). It might even be possible to do 32 kHz stereo if the SPC700 has enough power to decompress two channels of 8-bit audio while listening to the I/O ports, but even if it is possible I don't know if a custom algorithm that fast would sound any good...
...not that I'm exactly an expert on either audio decompression or the SPC700...
It occurs to me that any of these schemes should work with a single three-byte (plus counter byte) HDMA transfer every two scanlines rather than one or two bytes every scanline, allowing the SMP-side port monitor loop to run on a more relaxed schedule. I don't actually know how music engines work, but it seems to me that there should be enough free computing time to interleave a barebones sample playback routine...
Have I misunderstood something?
There are two ways I can think of this. One of them is via the echo buffer, and the other is by streaming BRR samples.
Perhaps you speak of a sound driver that simply loads two BRR samples (one for the left side and one for the right side), plays them at the desired sample rate and has a good sized buffer (make sure at the end of your buffer you have a loop block in there... you can just embed them in the sample)?
Blargg has an instantiation of
streaming lossless 32kHz stereo 16-bit audio to the SPC.
More practically, psychopathicteen implied he had an instantiation of streaming 22kHz mono BRR audio using just HDMA, freeing up the main CPU to do useful things.
KungFuFurby wrote:
There are two ways I can think of this. One of them is via the echo buffer, and the other is by streaming BRR samples.
The problem with streaming to the echo buffer is that you're forced to choose between low quality and high CPU time
twice.
First, storage - if you compress it, the S-CPU has to waste time decompressing it, and if you don't, well, you're storing uncompressed audio in the ROM.
Second, bandwidth - you can't DMA to the APU, and it's not fast enough to get data from more than one HDMA channel at a time, so if you want to feed it high-quality uncompressed audio you have to spend a lot of time in a handshake loop.
Now, I've never actually used the audio module, so maybe I'm missing something...
Quote:
Perhaps you speak of a sound driver that simply loads two BRR samples (one for the left side and one for the right side), plays them at the desired sample rate and has a good sized buffer (make sure at the end of your buffer you have a loop block in there... you can just embed them in the sample)?
I'm assuming it's pretty trivial to stream BRR once you know what you're doing (I don't). What I'm wondering is if there'd be enough processing time left to trigger additional highpassed 32 kHz samples for the crash, hat, snare, vocal sibilants and a few synth sounds that might need extra sparkle. That way we could do a decent imitation of 32 kHz 16-bit stereo without having to actually encode the whole song at that bitrate.
The third option would be to stream compressed 8-bit audio into the APU and have the SPC700 decompress it, saving to first order ~50% of the storage space at the cost of bit depth, but as I said I'm not sure how feasible that is or how good it would sound if it were...
lidnariq wrote:
More practically, psychopathicteen implied he had an instantiation of streaming 22kHz mono BRR audio using just HDMA, freeing up the main CPU to do useful things.
Why 22 kHz? It seems like that just fits into a single byte per scanline (with a couple kHz to spare); can't you use more than one I/O port?
You know, why is storage space such a big issue here? I'd much rather have superior audio quality, even if it means using a 32Mb cartridge... (Which there are enough of to use, if this even sees cartridge form.)
Difference between Mb and MB. The video data, as matters now stand, takes up more than 64 Mb (8 MB), and 32 kHz stereo BRR would take almost as much. So the lazy ideal case doesn't even fit in the memory map.
I got the decoder to work.
Now how is this going to fit into a ROM? It needs to extend between both slowROM and fastROM regions, but get around the 128kB of RAM right in the middle of it. I think we need to split the video into 2 parts, and have some jump in the middle when it gets to a specific frame. It needs a slightly better compression to fit in 8MB. Maybe if the tile map is processed vertically instead of horizontally, we can squeeze it in there.
In the mean time, can you make a shortened 1 minute version of the video, so I can test the frame rate?
93143 wrote:
Difference between Mb and MB. The video data, as matters now stand, takes up more than 64 Mb (8 MB), and 32 kHz stereo BRR would take almost as much. So the lazy ideal case doesn't even fit in the memory map.
Oh...

Well, I guess you could compress the video, but leave the audio in tact and it would maybe fit in a 96 megabit cartridge? (I'm not basing this on anything.)
psycopathicteen wrote:
It needs a slightly better compression to fit in 8MB.
Does it need to fit in 8 MB?
I mean, even if you get it down below 8 MB, you've still got no audio. And if the whole thing has to fit in 8 MB, you'd need to shrink the video a lot more than slightly before the audio would sound decent...
Espozo wrote:
Well, I guess you could compress the video, but leave the audio in tact and it would maybe fit in a 96 megabit cartridge? (I'm not basing this on anything.)
They're already compressing the video. If it turns out they've got spare CPU time, the question then is: how much
more can they compress it and still have the CPU be able to unpack it at speed?
Once the video is as small as it's going to get, we'll know how much space there is for audio.
psycopathicteen wrote:
I think we need to split the video into 2 parts, and have some jump in the

middle when it gets to a specific frame.
Bad Apple for NES put a special marker at the end of each 8192-byte bank's data that caused it to fetch the next frame from the start of the next bank. Once we get a full-size ROM, I could have it put such a marker after each 32K bank, which should allow use in both the low and high sections. I've made a copy of the first minute with each 32K bank padded out with $FF bytes.
I might investigate which 8x1-pixel slivers are most common. Allowing only 256 visually distinct slivers will slow decoding slightly and cause slight picture degradation but hopefully not too much.
I have the first half of Bad Apple working, but the frame rate jumps back and forth between 60fps and 30fps, depending on how much detail the frames are.
Is it supposed to jump between frame rates? it looks like the original video runs at 30fps.
My favorite part!
Attachment:
 Best Part!.png [ 3.05 KiB | Viewed 2210 times ]
Best Part!.png [ 3.05 KiB | Viewed 2210 times ]
Not half bad. The fact that some frames are running at 60 fps shows that you can spend some unused time on uploading audio to the SPC. But when I ran it in NO$SNS, I noticed that some frames appear to be exceeding vblank time, causing a flickering black band at the top of more complex white frames.
Attachment:
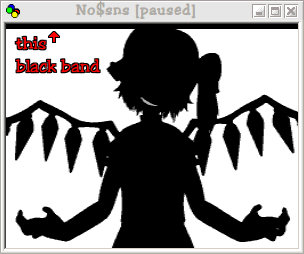 this_black_band.png [ 7.64 KiB | Viewed 2206 times ]
this_black_band.png [ 7.64 KiB | Viewed 2206 times ]
biggestframe.png has 394 tiles, which means 6304 bytes. This exceeds a single vblank, which means you'll need to spread the copy over two frames. But it also occupies only (394+2)*16*2+2048*2=16768 bytes of VRAM, which means you'll be able to double- or even triple-buffer the tiles easily.
I've got a few lossy approaches to try over the next week, including 4-bit slivers, 8-bit slivers, and a constant tile bank. If you want, can send you simulations of these approaches in the existing compressed format so that you don't have to modify the decoder to play them before we decide on a final codec to use. Did you use the $FF-padded version?
Are the multitrack masters of "Bad Apple" available? If so, then perhaps the instrumental parts can be converted to sequenced music. And it appears a lot of the track is repeated twice.
Looks nice.
But not in everything - I get a black screen in Snes9X v1.53, and garbage in higan v094. ZSNES v1.51 won't even load it. Seems to work fine in bsnes v072 and no$sns, but it's too big for my Super Everdrive so I can't test it on real hardware.
Attachment:
 half_bad_apple_higan_v094acc.png [ 2 KiB | Viewed 2185 times ]
half_bad_apple_higan_v094acc.png [ 2 KiB | Viewed 2185 times ]
Weird... EDIT: maybe it's because of the outsize memory map?
tepples wrote:
I've got a few lossy approaches to try over the next week, including 4-bit slivers, 8-bit slivers, and a constant tile bank.
Could sliver compression be done losslessly? How often would you have to refresh a sliver dictionary to catch all of them?
Is there an easy-to-decode form of compression, like RLE or LZ4 or something, that could be productively applied to the whole compressed data stream without blowing the CPU budget? It seems like LZ77-type compression with a big enough window would do interframe compression automatically, and there should be plenty of RAM for that, but I'm not clear on how much CPU time it would use...
I know you have no obligations to me here, and I am by no means a compression expert, but the MD version that originally sparked this idea was lossless, and I don't like the idea of giving up on matching it so soon. As you once said, "The trolls will still claim superiority"...
...
Maybe in a week or so I'll have enough time to fiddle with the audio track a bit, if KungFuFurby or someone like that hasn't already finished it...
Quote:
The fact that some frames are running at 60 fps...
Is it just me, or was there some actual slowdown in the part with Youmu and the tree? As in, below 30 fps?
EDIT: It seems to me that WRAM and VRAM combined should have enough room for a fairly substantial frame pipeline, if all else fails...
tepples wrote:
Are the multitrack masters of "Bad Apple" available? If so, then perhaps the instrumental parts can be converted to sequenced music. And it appears a lot of the track is repeated twice.
I don't know about multitrack (you'd have to ask Alstroemeria Records for that), but the CD release included a karaoke track. I have yet to attempt subtracting them to separate the vocals, so I don't know if the mastering was done in a way that makes it possible.
It's pretty easy to get a "multitrack" from the original sequenced music, if that would help.
I think we can use a library of the 256 most used slivers. We can use this format for tiles:
IRIRIRIRIRIRIRIR
I: 0=indexed sliver, 1=literal sliver
R: 0=repeat sliver, 1=new sliver
So the "top 256" format has little-endian, LSB-on-top control words where 00 is a repeat, 01 is indexed (one of the top 256 slivers), and 11 is literal (any other sliver), with a separate 512-byte table of the top slivers. I'll assume 10 is undefined. I'll post a 1-frame test image for this format tonight, and while you're working on getting a decoder working, I'll be working on converting the existing bitstream to the new format to see how much space it saves.
Tested with SD2SNES, just a black screen.
I wonder if these flash adapters are having trouble with the memory mapping.
Anyway, I did the top 256 slivers thing. The topd file contains frames encoded as described, while the tops contains the top 256 slivers. It didn't save as much as I'd thought (lossless: 6,070,886 bytes), possibly because of twice as many control words. Again, I've attached a 1-frame test and a larger test, not broken into 32K chunks. Do you want me to continue breaking it into 32K chunks?
Don't break it into 32k chunks, I'm using $400000-$7DFFFF and $C00000-$FFFFFF regions. I just need separate files for both halves of the video.
So you're not afraid to take the cycle penalty of frames whose decoding indexes across 64K bank boundaries. So anyway, I changed the "top 256" transcoder to produce 4 MiB chunks where no frame straddles a chunk boundary. The first file, which currently has the first 4360 frames, can go in $C0-$FF and the second in $41-$7D.
Now about the blank screens some of you are getting: The emulator or flash cart might not be loading the .sfc into memory in the same order as intended. This could be my impetus to write Holy Striker Batman, which helps the user determine how the emulator or flash cart is arranging the ROM image into the S-CPU's address space.
I can't figure out how to create a working 64mb ROM. How do emulators know the ROM mapping scheme anyway? I'm thinking they don't support sizes bigger than 48mb.
Not even the "all mighty" bsnes?
How are you currently assembling it? Mode 25h, theoretically, should have the 4MiB portion resident in $C00000-$FFFFFF first, followed by the 3.8MiB portion resident from $400000-$7DFFFF (and including the canonical header, which should be mirrored into $00FFB0-$00FFFF by hardware), followed by the last 64 KiB resident from $3E8000-$3FFFFF (maybe with two missing holes in the file? maybe not?).
Espozo wrote:
Not even the "all mighty" bsnes?
Older versions work. I tried it first in v072 and it was fine. And it's not the only one; no$sns works too.
Does the chipless hack of Star Ocean work in higan? Back in 2012, byuu
posted a memory map for it (XML, not BML). What about other emulators? I know it works on both SD2SNES and PowerPak, but how?
When you say "older versions work" are you implying that it doesn't work on newer ones?
I already said that on the previous page. I tried it in higan v094 and it gave me garbage.
The thing is, bsnes underwent a change a while back whereby it ceased to support community standards natively and switched to a "cartridge folder" format with a complete description of the contents of the cartridge, including the memory map, packed in along with the ROM. It can still import normal ROMs, but apparently it isn't as compatible with whatever psycopathicteen is doing as the old interface was.
...
Mode 25 seems like it should be fine as long as the whole thing stays below 63 Mbit. I suppose that depends on what ends up being done with the music...
93143 wrote:
I already said that on the previous page.
Attachment:
 ....png [ 50.14 KiB | Viewed 2387 times ]
....png [ 50.14 KiB | Viewed 2387 times ]
In other words, I might have to put codec development on hold to make a tool that displays what's going on in these emulators' memory maps.
Am I supposed to change the header? Would that fix it?
BTW, it does work in bsnes, but some parts of memory are inaccessible.
For mode 25h ("ExHiROM"), in the .sfc image, the header should begin at 0x40FFB0 (or 0x40FFC0 if it's not an extended header); the mode byte should be at 0x40FFD5, and it should either have the value 0x25 (2.7MHz = "SlowROM") or 0x35 (3.6MHz = "FastROM"). The rest of the bytes should be as I said in the previous post.
In contrast, Mode 21h "should" be limited to just 4MiB.
Espozo wrote:
93143 wrote:
Difference between Mb and MB. The video data, as matters now stand, takes up more than 64 Mb (8 MB), and 32 kHz stereo BRR would take almost as much. So the lazy ideal case doesn't even fit in the memory map.
Oh...
Well, I guess you could compress the video, but leave the audio in tact and it would maybe fit in a 96 megabit cartridge? (I'm not basing this on anything.)
You could create a version using the MSU-1 extension supported by SD2SNES, BSNES, and possibly NO$SNS?
Doesn't that kind of defeat the purpose? We're almost finished with this anyway. We got it compressed down to 48mb, with 16mb left over for audio.
I guess an MSU-1 video codec that takes care not to pull more than 150 KiB/s would be a counterpart to Sega CD: "This is what it would have looked like on the SNES CD had Nintendo not reneged on the deal with Sony."
psycopathicteen wrote:
We got it compressed down to 48mb, with 16mb left over for audio.
So you are going to try to fit it into 8 MB.
That still leaves enough space for a monaural version of the high-frequency sample augmentation idea. Alternately, if the vocals can be separated out as a mono track, sequencing part or all of the rest of the track (possibly including vocal sibilants) as was suggested earlier would probably fit it in without much trouble, and in stereo too, though it probably wouldn't sound as authentic.
If I were doing this, I'd probably have an alternate version prioritizing audio fidelity over memory map compatibility (I'm a digital music person). But it looks like we're already doing fairly well, with enough space to beat the MD version even with an unadorned mono BRR...
MottZilla wrote:
You could create a version using the MSU-1 extension
Of course. Possibly with higher resolution, and definitely with uncompressed Red Book audio. But that's cheating, at least until we've got a Sega CD version to compete with (and maybe even then)...
One of the Genesis versions compresses the sample to about 3 samples per byte, which is comparable to the ratio of the "MACE" audio codec from classic Mac OS. (I don't know how MACE works, but
I do know FFmpeg decodes it.) I have an idea for how to hack BRR to reduce the data rate to 2.5 bits per sample instead of 4.5, which the S-CPU expands to full BRR through lookup tables while feeding the S-SMP. It involves expanding 2-bit units to 4-bit nibbles using [-5, -1, 1, 5] or [-7, -2, 2, 7] depending on an additional bit in the shift amount byte. It's simple enough that the S-SMP could probably do the expansion itself with a lookup table or two. I haven't tried it for quality though.
Quote:
But [MSU-1 is] cheating, at least until we've got a Sega CD version to compete with (and maybe even then)
Perhaps it might inspire the Sega guys to try to beat us by creating a Sega CD version of the
color version.
Ehh... It's a bit ugly... (It doesn't translate very as well) I'm guessing this isn't anything official, because the animations on the models are a bit stiff and some models have a surprisingly low poly count. An apple or a tea cup with a model that detailed looks fine when it is far away, like in a video game, but it looks like I'm watching a red octagon spinning when it's full screen. Also, Super Road Blaster really mops the floor with anything the FMV "game" the Sega CD produced. But I really wouldn't say that hardware released in 1991 was really meant to compete with hardware 20 years latter.
(Even if both add-ons are still restricted by their parent hardware, which in that case, the SNES wins in terms of color.)
tepples wrote:
One of the Genesis versions compresses the sample to about 3 samples per byte
Yeah, I saw that one. Sounds pretty bad, but with 4 MB for video and audio combined it's a pretty impressive job nonetheless.
Quote:
I have an idea for how to hack BRR to reduce the data rate to 2.5 bits per sample instead of 4.5, which the S-CPU expands to full BRR through lookup tables while feeding the S-SMP. It involves expanding 2-bit units to 4-bit nibbles using [-5, -1, 1, 5] or [-7, -2, 2, 7] depending on an additional bit in the shift amount byte. It's simple enough that the S-SMP could probably do the expansion itself with a lookup table or two. I haven't tried it for quality though.
If that ended up sounding decent, it might be possible to combine it with the high-frequency sample augment scheme and get pseudo-32 kHz stereo. 16 Mbits is enough space for two channels at almost 15 kHz with a whole bank set aside for samples and program data.
I've been wondering about taking advantage of correlation between stereo channels to further compress a pair of BRR waveforms, but it seems complicated and I don't have time to think about it right now.
(This is all assuming the final video runs at 30 fps with enough headroom for APU handling, of course... I'm increasingly certain there's slowdown at several spots in the early version, but I can't get hard data because none of the emulators that have frame advance can run it...)
93143 wrote:
it might be possible to combine it with the high-frequency sample augment scheme and get pseudo-32 kHz stereo.
Has anyone looked at the "MP3+v" experimental codec as a proof of concept for high-frequency augmentation?
Quote:
I've been wondering about taking advantage of correlation between stereo channels to further compress a pair of BRR waveforms, but it seems complicated and I don't have time to think about it right now.
It's called "mid-side stereo". Encode (L+R)/2 at full rate and (L-R)/2 at a lower rate (lower frequency, lower ADPCM precision, etc.). Play L+R at full volume on both channels, and play L-R at 100% on left and -100% on right.
There are several approaches that can be used for the 32 Mbit version:
- Make a diagnostic tool to tell how the emulator is loading the ROM
- Audio with 2-bit BRR precision
- Use only 256 slivers
- Use only 16 slivers
- Reduce to 1024 distinct tiles, modulo hflip, vflip, and inversion, and store only nametable entries
tepples wrote:
Has anyone looked at the "MP3+v" experimental codec as a proof of concept for high-frequency augmentation?
Link? The Googles do nothing... Never mind; I found it. Well, a forum thread from 2001 and a dead site, anyway, but I think I get the general idea...
The scheme I'm thinking of is pretty simple, really:
1) highpass the original track at half the target samplerate,
2) browse through the resulting high-frequency track and make samples out of anything that sounds important,
3) program the SPC700 to trigger these samples at the appropriate times/volumes/etc. while playing back the downsampled track.
I figured I'd try doing the first two steps myself to see what the result looked like, but I won't have time until next week.
Quote:
It's called "mid-side stereo". Encode L+R at full rate and L-R at a lower rate (lower frequency, lower ADPCM precision, etc.). Play L+R at 50% volume on both channels, and play L-R at 50% on left and -50% on right.
Now that you mention it, it does seem kinda obvious - it's not like I've never messed around with mid-side before...
If your BRR hack turned out to work moderately well, using it on the side channel could result in nearly full quality streaming audio in a 12 MB ROM, assuming the decoded stream can be shoveled at the DSP fast enough. Alternatively, a sample rate reduction would accomplish roughly the same thing, though some high-frequency positional information would be lost.
I was imagining something more sophisticated somehow... but I guess there's a reason we aren't just using an MP3...
Espozo wrote:
Also, Super Road Blaster really mops the floor with anything the FMV "game" the Sega CD produced. But I really wouldn't say that hardware released in 1991 was really meant to compete with hardware 20 years latter.
(Even if both add-ons are still restricted by their parent hardware, which in that case, the SNES wins in terms of color.)
The Sega CD port of Road Blaster was pretty crap in the FMV department, it's like they just passed the FMV through a downsampler to 16 colors and that's it (it isn't even using multiple palettes, not to mention the reduced framerate). Pretty sure it could have been much better, but I guess they couldn't afford it.
At least everything else was alright, the new soundtrack fits the game better and they replaced the crappy dumb staff roll with a much better ending =P
How did most Sega CD games even deal with color? did they use multiple palettes, and possibly overlay BG layers for about 31 colors per tile? I'm guessing the screen wouldn't be able to have been updated in time.
Sik wrote:
At least everything else was alright
With "everything else" being two things.

Quote:
it's like they just passed the FMV through a downsampler to 16 colors and that's it
Well, it has dithering because, you know, dithering is
definitely a good substitute for not even using all the color palettes.

Is byuu around?
I need to know if this is the correct seek macro for exHirom?
Code:
macro seek(n) {
origin ({n} & 0x3fffff) | (({n} & 0x800000) >> 1)
base {n}
}
@Tepples, the "sba0topd" file is 4097kB. One kilobyte too big.
Espozo wrote:
How did most Sega CD games even deal with color? did they use multiple palettes, and possibly overlay BG layers for about 31 colors per tile? I'm guessing the screen wouldn't be able to have been updated in time.
Depends on the time when it was released actually, but usually three or four palettes would be used for FMV (the size and framerate of the FMV changed over time as the decoder evolved). Remember each tile could use its own palette.
There
is one game that does overlay two planes (Battlecorps), but it's not done for FMV =P (it updates at 15FPS, although it's just half the screen really)
Espozo wrote:
With "everything else" being two things.
It's not like there's much more to the game =P
Espozo wrote:
Well, it has dithering because, you know, dithering is
definitely a good substitute for not even using all the color palettes.
That's the issue, they didn't even bother with
that. There's a bit of dithering, but most stuff doesn't have dithering at all when it definitely was needed badly. In fact I wonder if the existing dithering isn't just a side effect of noise in the source video, because its patterns don't make that much sense either.
I think that shows how badly the conversion was.
psycopathicteen wrote:
correct seek macro
Lessee ... to convert a mode 25 physical ROM offset (accounting for the weird inversion of A23), it should be
0x000000-0x3FFFFF ↔ $C00000-$FFFFFF
0x400000-0x7DFFFF ↔ $400000-$7DFFFF (unchanged, usefully)
And explicitly choosing to ignore the range mapped to $3E8000-$3FFFFF
So,
#define logical2physical(addr) (addr | 0x400000 | (((~addr) & 0x400000) << 1))
psycopathicteen wrote:
@Tepples, the "sba0topd" file is 4097kB. One kilobyte too big.
Oops, my bad. It appears my chunker was defective: the first frame of a chunk would get repeated at the end of the previous chunk. Does the last kilobyte of the first file resemble the first kilobyte of the second file? If so, you can just chop it off. (Turns out it does; you can chop it at $3FFDF2.) I'll post new files if there are any other changes to make in the data.
Got the full video working. Now I have to get it running at a constant 30fps.
I managed to squeeze the compression routine into the last 256 bytes of Fast ROM.
It'll be nice to see if you can get that frame rate constant and audio working as well. Still impressive progress.
psycopathicteen wrote:
I managed to squeeze the compression routine into the last 256 bytes of Fast ROM.
If it'd be better with more tables, I could make the chunk slightly shorter.
Really impressive to see it coming on the SNES
Also the latter version of the ROM work on almost emulator so we can test it easily.
Before trying to reduce too much the size of the rom, you should really consider the unpacking time on the CPU.
Some frame can be really heavy to unpack (thinking about the tree or the fire screens) and if you look the MD version you will see 2 or 3 locations where the frame rate drop at ~25 FPS instead of 30 FPS. The MD version it is not optimized at its best (i stopped when i assumed it was "good enough") but still i admit that i am wondering how you will be able to push that much data with the 65816 (if you really want to keep the codec lossless and fit that in 8MB with sound) but i am really looking forward your progresses =) Actually your codec looks already better that what i did ! It did not compress as much but it does compress very well and looks not over complicated
I've been working hard on this today, and there's slowdown in one spot that I can't seem to fix. It's during the part with the 3 musicians. I'm going to use DMA to speed up RLE name table decompression, so I'm requesting a slight change to the compression algorithm.
Instead of the CPU knowing automatically where the name tables end and the pattern tables begin, it would be faster if there's an exit byte 11xxxxxx, at the end of name tables, followed by a word with the number of pattern tiles in the frame.
I've looked at the binary. From what I can see, your RAM consists of variables at 0000xxh, and a bigger buffer at 7E2000h+x.
The variables are sometimes accessed as [xxh], sometimes as [00xxh], and sometimes as [0000xxh]. Always using 8bit addressing [xxh] should be faster. Why didn't you do that? Or is the assembler automatically doing that?
Moving the variables from 00xxh to 43xxh should be also faster (by setting the "zero page" bank to 4300h, and then accessing them via 8bit addresses [xxh]. The internal Work RAM at 00xxh is slow. Mis-using the DMA registers as storage is faster.
And for the big buffer, setting DB=7Eh as bank number, and then accessing it as [2000h+x] should be faster than accessing it as [7E2000h+x]. As long as you don't need "DB" for other purposes.
This is the latest version. It has optimizations all over the place, and I still can't get rid of the slowdown in that one spot.
Tonight I plan to regenerate the compressed data with the following changes:
- Chunk size is $3F0000 = 4128768 bytes (4 MiB minus 64 KiB) to allow code in fast ROM
- End each nametable with a 2-byte command
110000bb then aaaaaaaa: b*256+a compressed pattern tiles follow
That sounds like a good idea. Does the 110000bb byte comes first, followed by the aaaaaaaa?
psycopathicteen wrote:
This is the latest version. It has optimizations all over the place, and I still can't get rid of the slowdown in that one spot.
To be honest i am really impressed
Very well done, almost full speed on the whole video ! I guess with some minors adjustments you can get it
I wonder how much room you have for the sound... but you can always find solutions =)
Did you tested it on real hardware ? is it possible to have the code source ?
Works great on real hardware.
psycopathicteen wrote:
That sounds like a good idea. Does the 110000bb byte comes first, followed by the aaaaaaaa?
Yes, big-endian.
But I'm not sure why you need this length when you already have the length from having built the nametable. How exactly would that make decoding faster?
Can you read from DMA registers, and $2181-$2183? Because if that is the case, I can find the end of the tile map by looking at $2181-$2183, and find the amount of tiles by looking at what address the DMA channel left off.
Looking at
http://problemkaputt.de/fullsnes.htm , DMA registers are readable, but not $2181-2183 (which are the WRAM address registers).
DMA registers are readable, or
blargg's serial code wouldn't work.
When you build the nametable and hit a $80-$BF opcode, where are you storing the number of the next unique tile? I'm just trying to decide what advantage I could have for 11000000 over 110000bb bbbbbbbb.
Quote:
Where are you storing the number of the next unique tile?
Address $004322
So the program can predict the number of tiles to decompress from the number of the last unique tile in the nametable. I have been maintaining a test decompressor for each format change to test the compressor, and it just uses the 110000xx xxxxxxxx end mark as an assertion of byte stream consistency.
Here's the data in the agreed format. It still leaves enough space for mono BRR at 16 kHz.
What frame does the first chunk end on?
I believe there are 4292 frames in the first chunk.
My high-frequency enhancement scheme seems promising. I've isolated highpassed samples for the crash, hi-hat, kick(/snare?), s, k, t, and ch/j. The crash is nearly 14 kB, which is more than half the total, but it loops nicely. The BRR compression results in a very high broadband noise floor - only 25 dB below the signal peak in the case of the crash - but there's enough going on in the main body of the track that a bit of extra noise doesn't really stand out.
Here's a comparison of the first few beats with and without the enhancement. The main track is at 16 kHz, and the crash/hat/drum are at 32 kHz; all components have been separately passed through BRRTools. Mix positions for the samples were chosen by eye at moderate zoom, to rule out unreasonable precision requirements.
Attachment:
 hifreq_comparison.rar [127.21 KiB]
Downloaded 144 times
hifreq_comparison.rar [127.21 KiB]
Downloaded 144 times
I'd kinda like to be able to do the squiggly synth sound that sometimes accompanies the crash at the beginning of a section, but it's very difficult to isolate and I don't believe in my ability to reconstruct it from scratch (I'm not a synth guy)...
Unfortunately, I looped the crash cymbal before attempting any sort of compensation for rolloff, so I will probably have to do it again...
...
Speaking of which: I copied
this filter into Matlab and got the attached plot.
1) Is this what it's supposed to look like? It's been a while since I studied digital controls and signal processing... (The x-axis is actually Hz, not rad/s...)
2) If this is right, are the peak and high-frequency falloff part of the intended behaviour, or are they artifacts of the fitting method (ie: would the ideal curve keep going up)? What does the function it's supposed to be compensating for look like? What sort of error magnitudes should I expect from this?
Attachment:
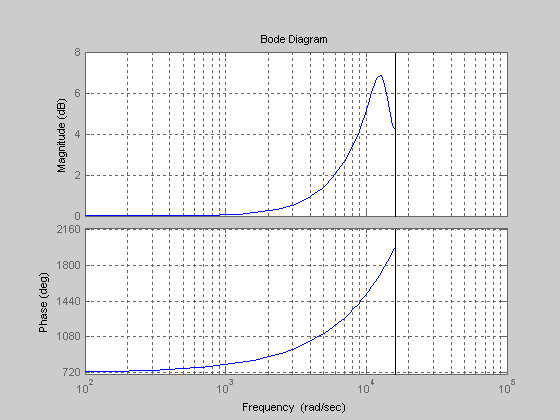 trans.png [ 14.69 KiB | Viewed 2483 times ]
trans.png [ 14.69 KiB | Viewed 2483 times ]
Also, I've noted that when filtering the track through BRRTools, using -g for both encoding and decoding results in a much duller sound than not using it for either, to the point of sounding noticeably worse when enhanced. (The material in the example was not pre- or post-filtered).
Now it always crashes during the fire part for some reason. I tried tracing it in the debugger, and it looks like the CPU gets screwed up hitting a #$ff byte that is not supposed to be there, and it ends up doing 768 tile patterns, which overflows from one frame buffer to another. I'll try overwriting it to make it with #$c0, and see if that fixes it.
I have identified a problem in my encoder where a completely white frame would register as -1 tiles instead of 0 tiles. Internally in my encoder, $0000 is the all-white tile, $0001 is the all-black tile, and pattern tiles start at $0002. In any frame, the number of pattern tiles is equal to the maximum tile number in the image minus 1. For example, if the highest tile number is 295, there are 296 tiles, of which all but the first two are encoded, for a pattern table length of 294 tiles. This assumption fails for all-white frames such as frame 2707 (2727 in the original video; mine trims 20 leading black frames).
The fix is to edit all $FFFF pattern table length words to $C000. I have fixed my encoder and tested the fix.
93143: The preemph filter I made for that post is a symmetric FIR filter, and all symmetric FIR filters are linear phase. Try graphing it with linear frequency, not log frequency. The function it's compensating for is the
"4-point Gaussian interpolation" in Fullsnes. The peak and high-frequency rolloff are an artifact of using only 15 taps; an ideal filter would continue up to +11 dB.
Brilliant , Fantastic , really impresive!
Cant wait to see ( or hear) the demo with sound

.
psycopathicteen , tepples and 93143 , you are reallly skilled , thank you.
I hope that , some far away day, I can be close to that level of ability.
I tested the ROM on my SNES:
PAL , CPU: 02 , PPU: 01 , PPU: 02
Powerpack , firmware v2.02.
It works without any problem , but a 17% slower.
Okay, I implemented the interpolator in Matlab, and it looks like it works. It's hard to get an accurate picture of what's going on with non-integer resampling factors, because the FFTs no longer map nicely and the curve obtained by subtracting the power spectra gets buried in noise. (I suppose I could try a moving average...) But from just plotting the power spectra on top of each other, it does seem like the behaviour is fairly consistent.
Consistent, but not frequency-independent. If my code is right, even after correcting for input sample rate there's a bit of extra rolloff on 16 kHz data.
EDIT: I tried a moving average. The 22.05 kHz case tracks the 16 kHz one. Just so we're clear, this plot is normalized to the Nyquist frequency for the
input data.
Attachment:
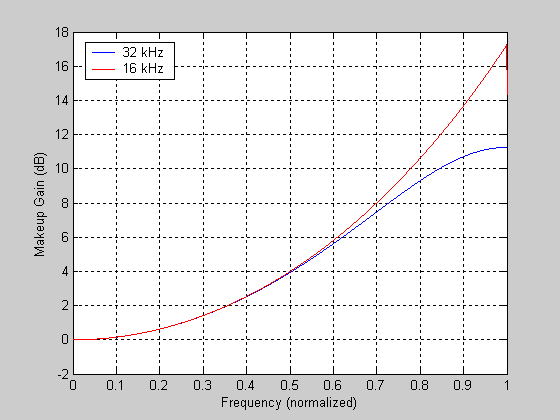 snesgain_norm.png [ 11.83 KiB | Viewed 2308 times ]
snesgain_norm.png [ 11.83 KiB | Viewed 2308 times ]
I guess now I have a pretty good idea of what needs to be done to the audio before it's converted. EDIT: Got some settings figured out in PLParEQ3, for both 16 kHz and 32 kHz. On white noise, using the equalizer followed by the gaussian results in +/-0.2 dB of ripple in the top end for both cases, which is more than good enough.
...
Who's writing the audio engine for this thing? I haven't accidentally volunteered myself, have I?
I'm waiting for Tepples to post the fixed version of the compression data.
Well, I may be jumping the gun a little with this exercise, but I've converted the samples. Attached (in case anyone cares at this point) are BRRs of the crash cymbal, hi-hat, snare/kick, ch, k, sh, and t. IIRC the k and t were taken from around 5:00-5:01 in the long version, and the ch and sh are from 2:01 and 2:17 respectively. The crash is from 0:13 (heavily processed of course), and the hat and snare are from somewhere before that.
Attachment:
basamples_v1.rar [27.06 KiB]
Downloaded 151 times
The volume of the samples has not been altered (except incidentally via prefiltering), so they will have to be taken down a bit to fit the streaming audio. When I put a 16 kHz mono version of the original track through my custom prefilter, the peak amplitude went up by nearly 5 dB.
[The BRR compression really does a number on this stuff... kinda makes me wonder if it's worth all the precision I put in the front end...]
...
I don't get the same results from my gaussian interpolator as from BRRTools with -g turned on. And it's not a small difference; using -g instead of my version makes the whole high-frequency augmentation scheme not work very well. I'd think I did it wrong, but the curve I get at 32 kHz matches tepples' description (plus, tepples' filter is in BRRTools, and as I said before, using -g for both encoding and decoding muffles the output). So I looked at the source code for BRRTools and found this:
Code:
void apply_gauss_filter(pcm_t *buffer, size_t length)
{
int prev = (372 + 1034) * buffer[0] + 372 * buffer[1]; // First sample
for(unsigned int i=1; i < length-1; ++i)
{
int k0 = 372 * (buffer[i-1] + buffer[i+1]);
int k = 1034 * buffer[i];
buffer[i-1] = prev/2048;
prev = k0 + k;
}
int last = 372 * buffer[length-2] + (1034 + 372) * buffer[length-1];
buffer[length-2] = prev/2048;
buffer[length-1] = last/2048;
}
This doesn't look at all like what anomie and nocash describe. It just looks like a symmetric smoothing filter with gain reduction. Did I miss something? What's going on here?
Under the nocash stuff, a Gaussian interpolation aligned to sample boundary will produce [$176, $519, $172]/2048 which is [374, 1305, 370]/2048 which slightly exceeds unity gain at DC. I normalized this in my own BRR decoder to [372, 1304, 372]/2048, which incidentally is very close to [2, 7, 2]/11.
What apply_gauss_filter appears to be doing is convolving with [372, 1034, 372]/2048. I think there's a bit of a typo going on here (1034 when 1304 is intended), and this is causing the muffling you're hearing.
Is source code for your prefilter available?
I should have looked closer when I saw that "/2048"...
Source code for the prefilter? No, unfortunately. I'm using PLParEQ3, a cut-down version of PLParEQ which is apparently not available any more. The full version seems to be in the "if you have to ask, you can't afford it" category, which is a far cry from the $20 I got my copy for back when they were fishing for donations. I can post the settings for 16 and 32 kHz if you like, but I imagine a more general (and portable) formulation would have been more useful...
I did test my scheme on white noise, following up with my implementation of the 4-point interpolator, and the result was +/-0.2 dB of ripple versus the original spectrum. And I can't hear a difference, not in the brightness at least. So unless my interpolator is wrong, or I made a really weird error somewhere else, I'd say the prefiltering is doing what it's supposed to.
Here's the interpolator, in Matlab (a bit of a lazy hack, but aside from the phase alignment it should be okay):
Code:
function X32 = gsnes(Xin,Fs);
gausstable;
X = Xin;
X(end+1:end+3) = Xin(1:3);
p = floor(4096*Fs/32000);
pcount = 0;
S = 4;
i = 0;
X32 = zeros(floor(length(Xin)*32000/Fs),1);
if mod(length(X32),2),
X32(end+1) = 0;
end
for I = 1:length(X32),
X32(I) = (gtable(256-i)*X(S-3)/1024 + ...
gtable(512-i)*X(S-2)/1024 + ...
gtable(257+i)*X(S-1)/1024 + ...
gtable(1+i)*X(S)/1024)/2;
pcount = pcount + p;
S = 4 + floor(pcount/4096);
i = floor(pcount/16) - floor(pcount/4096)*256;
end
The gausstable macro just defines gtable; it's essentially a copy/paste of the table in fullsnes with a bunch of "hex2dec" syntax inserted. I see no point in reproducing it here.
Then what's the impulse response of your expensive prefilter? For example, if I pass the sample [..., 0, 0, 16384, 0, 0, ...] through it, what do I get?
I think I'll just stick to plain vanilla 16kHz BRR for now.
tepples wrote:
Then what's the impulse response of your expensive prefilter? For example, if I pass the sample [..., 0, 0, 16384, 0, 0, ...] through it, what do I get?
...I'm really not thinking things through here. I'm chronically behind on my research, so I end up in a mild panic whenever I do anything else.
The impulse responses are different for different input frequencies, as I mentioned earlier. I only did 16 and 32 kHz; here are the full impulse responses at 24-bit resolution:
Attachment:
gpre_ir.rar [5.55 KiB]
Downloaded 162 times
The 16 kHz one clipped when I used 50% amplitude as an input, so I went with 25% for both.
Since the filtering is done at the specified input sample rate, rather than at a higher rate for later resampling, the 16 kHz one should be applicable at a range of sample rates as long as they don't approach 32 kHz. If the response near 32 kHz works the way I suspect it does, it's probably not hard to come up with a differential filter that could be applied before resampling or something like that, so that the lower-rate filter would then work across the whole range, but I really have to stop this for the moment and do some work...
psycopathicteen wrote:
I think I'll just stick to plain vanilla 16kHz BRR for now.
That's probably a good idea. In addition to complicating the sound driver, this scheme requires
somebody to do a lot of fiddly sequencing; I really don't have the time right now and I can't really ask anyone else to do it. (I was hoping someone with actual SPC700 expertise would take an interest and volunteer, but...) Plus, since it doesn't require any extra CPU time, it won't disturb the video codec, meaning it shouldn't be especially hard to add in later.
How do you plan to stream the audio?
I hesitate to bump this thread, but I don't want this stuff scattered around the forum, and anyway it's not a whole lot less relevant to the topic than it was the first time...
I've modified my 16 kHz filter slightly, adding a very narrow 1.1 dB cut at 7,860 Hz. You might not hear a difference, but it now meets the +/- 0.2 dB ripple spec right up until the plot starts to go nuts in a case-dependent fashion a little past 7.8 kHz. The IR is significantly longer than the first version, possibly because the new filter is very steep, or possibly because I ran out of filter slots in PLParEQ3 (it's in the name) and had to use a second instance, so the up- and down-sampling was done twice.
Attachment:
gpre_ir_v2.7z [19.94 KiB]
Downloaded 102 times
93143 wrote:
I'd kinda like to be able to do the squiggly synth sound that sometimes accompanies the crash at the beginning of a section, but it's very difficult to isolate and I don't believe in my ability to reconstruct it from scratch (I'm not a synth guy)...
Never mind; it wasn't that tough after all. A high-frequency sine wave with strong triangle LFO pitch modulation at ~18 Hz seems to work well enough, particularly with some reverb added.
The new sample is well over a second long, with the result that the whole sample pack is now 54,468 bytes. It's not all that tough to get a half-decent-sounding loop, but I'm probably not going to try to optimize until it's clear there's a need.
Attachment:
basamples_v2.7z [48.8 KiB]
Downloaded 104 times
Oh, and the new sample is much louder than it should be with respect to the other samples, because it was synthesized rather than lifted from the (CD version of the) track itself. My excuse is that it's better to use one's ears at mix time rather than attempting to gain-correct things
a priori and getting them slightly wrong but not wrong enough to notice until it's too late...
Is there some kind of glitch in BSNES that doesn't allow the 65816, SPC700 and DSP to do be properly synced at the same time? I can get it to run code that alters the BRR samples in real time, and have the 65816 transfer data to the SPC700 in real time, but not both at once.
93143 wrote:
The IR is significantly longer than the first version, possibly because the new filter is very steep
That's exactly why. The sharper the filter, the longer it takes to determine whether any given input frequency is affected or not.
Cool. Getting closer...
Are you just using a tight loop then? That would certainly explain the extra slowdown. The reduced pitch does make it nicer to watch through to the end, since it kind of stays in sync (it crashes to a garbage screen after finishing).
Also, there seems to be fairly regular popping in the audio, which I assume is not part of the data itself. Could it be related to bank boundaries?
How much spare CPU time do you have without the music? Did you manage to completely eliminate the slowdown? I figure it should be possible to use HDMA to get the audio overhead down to a few percent of a frame.
psycopathicteen wrote:
Quote:
Speaking of which, how's that Bad Apple demo going?
I had difficulty programming the compression encoder, since I am not used to high level languages.
I did notice that it can be compressed a lot, just by doing RLE on 8x1 slivers in a vertical direction. Using per pixel LZSS looks a bit overkill to me.
Hi guy, you have a full lz4 compressor(PC side)/decompressor for 65816 here :
http://www.brutaldeluxe.fr/products/crossdevtools/lz4/All is very well explained,if it can help you .
psycopathicteen wrote:
http://s000.tinyupload.com/index.php?file_id=11212367878411147693
http://www.megafileupload.com/796/BadApple.zipI got the music working, but it doesn't use the HDMA trick.
Cool to see it happen, really close indeed, well done
I used No$SNS 1.5 to play it and i got some garbage in sound, i guess it comes from the emulator... which emulator is the best suited to emulate properly here ? Higan maybe ?
psycopathicteen wrote:
http://s000.tinyupload.com/index.php?file_id=11212367878411147693
http://www.megafileupload.com/796/BadApple.zipI got the music working, but it doesn't use the HDMA trick.
wahou, congrats i'am speechless, really

...
Stef wrote:
I used No$SNS 1.5 to play it and i got some garbage in sound, i guess it comes from the emulator... which emulator is the best suited to emulate properly here ? Higan maybe ?
I used higan (balanced, of course - my laptop can't keep up with accuracy core). It pops every few seconds, but nothing like the mess no$sns makes. And of course the pitch is a bit low; I assume this is a temporary measure to compensate for the slowdown.
Snes9X freezes, and ZSNES doesn't even start. I can't run it on a real SNES; my Super Everdrive complains that the file is too big...
Cool thanks, i will try that on Higan then
Is there any flashcart supporting 8 MB file on SNES ?
Edit:I guess i have my reply :
viewtopic.php?f=12&t=4380&start=75
SD2SNES and PowerPak can handle 8 MB or even 12 MB (the Star Ocean hack) just fine.
I should have checked more carefully; I thought the Super Everdrive could handle 8 MB, but the manual says 7 MB. Darn it...
Too bad, i had the same surprise with my everdrive. I though it can handle 8 MB rom because it has 8 MB flash but it does only support 6 MB max :-/
Is there any synchronization (using APU timers, or ENDX flags)? I can't see any such thing, the APU code seems to be receiving any incoming data, and "blindly" writing it to sound RAM.
Synchronization is required because the APU uses a different osciallator than main cpu & video, and the APU clock should be rather inaccurate since it's only having a ceramic oscillator, which may be faster/slower on different consoles (not too mention factors like different temperatures).
One approach would be using the APU clock as master: waiting (or frameskipping) at main cpu side whenever the APU has complete one audio frame.
And maybe better would using the main CPU clock as master: in that case you would need to brew up something that does dynamically increase/decrease the BRR sample rate as needed (ie. if the sound engine completed the sound-frame faster or slower as expected by the main cpu, then adjust the BRR rate accordingly). This approach might be a little more complicated, the advantage would be that the audio clock is effectively derived from the (more accurate) main cpu's crystal - so you would gain better precision than normal SNES audio.
The S-DSP supports setting the playback sample rate only in 7.8125 Hz increments.
It runs on my PowerPak, but there's some horrible rumbling while Marisa is on the broom.
That sounds like what no$sns does. It sounds to me like it's intermingling two different banks or something, and then restarting the one it was supposed to be playing (resulting in a desync); I assumed it was just the emulator because higan doesn't do it, and higan is usually more accurate. (The problem section also doesn't match up with the pops - I guess at least one of my suspicions is wrong...)
There's also a graphical glitch a couple of seconds in, that wasn't there in the silent version.
Saved 3 kB on the looped cymbal, without making it sound terrible. Total is now 51,399 bytes.
Again, the synth sample does not match the gain on the rest of the samples. Also note that even the rest of the samples do not necessarily match any given rip of the original audio (the video version is a bit louder than the CD version).
Attachment:
basamples_v2.1.7z [46 KiB]
Downloaded 115 times
I tried to sequence this in OpenMPT a while back, but the classic tracker timing just isn't precise enough; the hits don't even stay glued together for the first four bars. One could tweak the main track's playback speed, but over a three-and-a-half-minute song I can see that adding up to a video sync issue. Maybe I should take another look at it, but I suspect it may be better to write a simple driver first and sequence directly in hex without reference to a tempo...
I just found out a lot of time is spent waiting for vblank. It looks like using a frame queue was not as useful as I thought it would be.
You mean you wai after completing a frame? Does that mean you can speed it up by proceeding immediately to the next frame if there's a free slot, instead of waiting? Or does it already only wait after the queue is full?
It only waits when the queue is full, and it gets filled up pretty quickly.
I'm kind've fed up with streaming right now. I wonder if I can compress the audio to fit into 64kB by increasing the tempo 32 times faster, and then artificially slow it back down with channel fading.
Now that I think of it, waiting after every frame would simply not fill up the queue, and I've seen the full frame queue in the no$sns debugger. So I guess that was a silly thing for me to say...
Quote:
I wonder if I can compress the audio to fit into 64kB by increasing the tempo 32 times faster, and then artificially slow it back down with channel fading.
Well, I just tried that approximate procedure with both Dirac and paulstretch, and uh, I suspect it's not going to work very well. I didn't exhaustively optimize (I was using a primitive Dirac implementation and had to use 5 passes each way, and paulstretch has at least one free parameter I didn't spend much time with), but from what I got it doesn't look promising:
Attachment:
basquash.7z [1.38 MiB]
Downloaded 140 times
I tried speeding it up with ADM Studio Time, but it tried to be clever about the re-expansion so I had to use paulstretch for that, and it didn't work any better. Using Studio Pitch (which is conceptually the same thing) produced a final result of the correct length, but it was still pretty bad; the 100% paulstretch one is the best result so far.
You've got to lose something when you compress, and if you're keeping the frequency information you lose time resolution. A really nice algorithm used well might produce something recognizable, but it wouldn't fool anybody.
...
Oh, hang on - are you transferring a constant amount of audio per frame? Maybe you could use the whole audio RAM as a buffer, and fill it up when you've got time... would that be easier than trying to make HDMA work? This would break my high-frequency augmentation scheme, but we can worry about that later (if you were ever worried about it in the first place)...
Re: HDMA, have you looked at the N-Warp Daisakusen source code?
...I hope my backseat driving isn't too offputting... I'm not the one who's been beating his head against this for months, so I'm still pretty enthusiastic about it...
is there a nice guy which can patch the ROM file to test on tototek flashcart ? Thanks
EDIT : size is incorrectly detected by flasher program (2mb instead of 64)
psycopathicteen wrote:
I think we can use a library of the 256 most used slivers. We can use this format for tiles:
IRIRIRIRIRIRIRIR
I: 0=indexed sliver, 1=literal sliver
R: 0=repeat sliver, 1=new sliver
Hey Tepples? You still have the compression codec? I found an optization.
If the sliver is being repeated, there doesn't need to be an "I" bit. Memory to memory shifts use a lot of cycles.
In a packet with a skipped I bit, what is the empty bit used for?
It just pads the end with 0s, like this.
0000RRRRIRIRIR or
00000000RRRRRRRR
It works, but it still didn't get rid of all the slowdown.
Indexed slivers take the longest to calculate so maybe there can be a limit to how many indexed slivers per frame.
EDIT: Screw it, it's close enough.
http://www.filehosting.org/file/details ... 0Apple.zip
That's pretty good. Way more polished than last time, and the timing almost works even with the music at its original pitch. Little muffled; I see you've dropped the sample rate to 12 kHz...
I figure there are at least two methods still available to reduce the impact of the audio streaming without losing quality, but I mentioned both of them just upthread from here so I won't belabor the point. Combined with your suggestion that the video decoding speed could still be improved, it seems to me that there may be a decent amount of headroom left. I'm encouraged.
Again, I don't mean to rush you or harass you - it's great that you're doing this at all.
...
Could the encoder use some sort of complexity heuristic to determine when it's necessary to limit the number of indexed slivers, so as to minimize file size growth? Or would that be too hard to program and/or totally unnecessary? It just seems like there are only a couple of spots left that are still giving trouble...
Would it be useful to add a fourth type of sliver that contains only black pixels or only white pixels? I imagine that those would be faster to process, despite having to going back to shifting out two bits per sliver, because they require no lookup. Or are the slow parts the parts with a lot of gray areas and no hard lines?
There can be an extra byte that determines whether each black or white sliver, is black or white, that comes after the "IRIRIRIRIRIRIRIR" word. 0 being black, 1 being white.
For black slivers I can just use a stz $0000,x, and give a special loop for repeated slivers that come after black slivers.
My previous post was confused.
I meant slivers that are all black-and-white, no gray. That way you can just store the sliver index to the tile twice instead of having to look it up through a LUT. This makes four choices: a 2-byte sliver, a sliver with both bytes the same, an indexed sliver, or a repeat. Or if storing a byte followed by a zero is faster than storing the same byte twice, I can encode the video to exchange white with dark gray in the palette. Is there a best set of four codes for this set of four possibilities?
I like the idea of switching the order of the grey scale.
The video we've been using has a lot of antialiasing on it. Are you going to sharpen it up a little so there are more black and white edges?
I could sharpen up tiles containing mostly black and white pixels, but then it wouldn't be quite as "lossless". Heck, it might not even need it.
14986 of 65280 distinct slivers containing gray used in 6532 frames
Slivers with only black and white cover 895890 of 3438683 sliver changes
and of the 2542793 with gray, the top 256 with gray cover 2250151
I've made a new encode, using the following meanings of each 2-bit unit of the 16-bit control word:
00: repeat sliver
01: indexed sliver
10: 1-byte sliver (second byte 00)
11: 2-byte sliver
The palette has been changed to black, white, light gray, dark gray as described. I can change it back if storing a single byte twice turns out to be faster than storing a byte followed by a 0.
Which parts of the video slow down the most? Are they the parts stored in slow ROM? Or are they the parts with the most gray?
Quote:
Which parts of the video slow down the most? Are they the parts stored in slow ROM? Or are they the parts with the most gray?
Parts that involve demons with tree branches for wings making a creepy smile and zooming into the camera.
Second character after cup breaks, branchlike wings, evil smirk at 0:55?
Stack Exchange says her name is
Flandre Scarlet. She's a vampire with wings that don't work for flight, and her own theme song is "U.N. Owen Was Her?" (aka "McRoll'd").

Everything she touches, she breaks. (Including your decoder.)
Can your decoder "decode ahead" to a circular buffer in WRAM, or is its buffer limited to one frame? I wonder if I could add some judicious "repeat previous frame" opcodes to the parts known for slowdown.
tepples wrote:
I wonder if I could add some judicious "repeat previous frame" opcodes to the parts known for slowdown.
You mean drop the encoded frame rate, losing data? Seems like a desperation move to me; surely the situation doesn't warrant such a thing quite yet...
Or do you mean "repeat the decoded sliver/tile from last frame"? That sounds like it would be way faster if it
didn't use a multi-frame buffer...
...and yes, it does. From what I can see in no$sns, WRAM and VRAM are divided into 8 kB pages; I guess that would be two ring buffers. Apparently they fill up pretty quickly and stay that way except in the most intense sections. This is what suggested to me the idea of using most of audio RAM as a music buffer - it seems there's a lot of free time in the easy parts of the video, so with a large audio buffer it might not be necessary to stream audio at all during the hard parts.
...
I just realized something.
I've been reluctant to push the large audio buffer idea because it rules out my high-frequency enhancement trick with the highpassed samples. But if there's DMA running during active display - and it looks like there is - using HDMA for audio would almost certainly break the demo on consoles with the DMA/HDMA collision bug. So if you need to modify the audio streaming to mitigate or get rid of the slowdown (not unlikely from where I sit), and you're going for 1/1/1 compatibility (I would), I guess I can forget the enhancement idea...
I don't know if you are aware of it but :
https://www.youtube.com/watch?v=ASUsvXTNgIgI'm not a big fan of the added echo effect but definitely this is a nice accomplishment. Frame rate seems to drop a bit below 30 FPS in some areas but actually even the Megadrive version has a bit of FPS drop (in 2 parts actually).
I would really like to have more information about the implementation
The biggest difference between that and the one from last time is I unrolled the SPC700's fetching code, so the 65816 doesn't have to wait so long for it.
Here's the SPC side loading code:
Code:
macro fetch_samples(x) {
ldw $f4
str $f6=#{x}
stw {x}
}
This gets repeated over and over again with a different "x" value.
65816-side spc loading code:
Code:
spc700_streaming:
sep #$30
ldy #$00
ldx #$00
lda [{brr_stream_address}],y
sta $2140
iny
lda [{brr_stream_address}],y
sta $2141
iny
lda #$01
sta $2143
rep #$20
lda [{brr_stream_address}],y
-;
cpx $2142
bne -
sta $2140
tyx
iny
iny
lda [{brr_stream_address}],y
cpy #$e0
bne -
-;
cpx $2142
bne -
sep #$20
sta $2140
stz $2143
rep #$20
lda #$00e1
clc
adc {brr_stream_address}
sta {brr_stream_address}
bcc +
inc {brr_stream_bank}
+;
rts
Here's the meat of the compression:
Code:
compress_planar_tiles:
lda [{address}],y
sta {rle_buffer}
iny #2
txa
clc
adc #$0010
sta {counter}
lda {bit_plane}
planer_compression_loop:
lsr {rle_buffer}
bcs new_tile
old_tile:
sta.w {bg_map},x
inx #2
cpx {counter}
beq finished_tile
lsr {rle_buffer}
bcc old_tile
new_tile:
lda [{address}],y
lsr {rle_buffer}
bcs literal_tile
indexed_tile:
and #$00ff
asl
sta {index}
lda [{index}]
iny
sta.w {bg_map},x
inx #2
cpx {counter}
beq finished_tile
lsr {rle_buffer}
bcs new_tile
sta.w {bg_map},x
inx #2
cpx {counter}
beq finished_tile
lsr {rle_buffer}
bcc old_tile
lda [{address}],y
lsr {rle_buffer}
bcc indexed_tile
literal_tile:
iny #2
sta.w {bg_map},x
inx #2
cpx {counter}
beq finished_tile
lsr {rle_buffer}
bcs new_tile
bra old_tile
finished_tile:
sta {bit_plane}
dec {tile_number}
bne compress_planar_tiles
Quote:
I could sharpen up tiles containing mostly black and white pixels, but then it wouldn't be quite as "lossless". Heck, it might not even need it.
14986 of 65280 distinct slivers containing gray used in 6532 frames
Slivers with only black and white cover 895890 of 3438683 sliver changes
and of the 2542793 with gray, the top 256 with gray cover 2250151
I've made a new encode, using the following meanings of each 2-bit unit of the 16-bit control word:
00: repeat sliver
01: indexed sliver
10: 1-byte sliver (second byte 00)
11: 2-byte sliver
The palette has been changed to black, white, light gray, dark gray as described. I can change it back if storing a single byte twice turns out to be faster than storing a byte followed by a 0.
Which parts of the video slow down the most? Are they the parts stored in slow ROM? Or are they the parts with the most gray?
Does this really eliminate the need for indexed slivers, or is it supposed to leave extra room so you could put a limit on indexed slivers without it bloating up?
psycopathicteen wrote:
Does [addition of 1-bit slivers] really eliminate the need for indexed slivers, or is it supposed to leave extra room so you could put a limit on indexed slivers without it bloating up?
The latter is my intent.
Thanks psycopathicteen for the details =)
I'm really impressed by the size of the code, is this really all the code for unpacking ? I didn't read it yet but it looks really small.
What impress me the most (beside you were able to do it on the SNES :p) is you were able to make it fit in 8 MB with a much simpler compression scheme that i used for the MD version (i use different kind of compression, both for the tilemap and for the tiles) so now i really think about reworking it with better compression format :p What help a lot here is the native 2bpp format, on MD i had to fake it and encode 2 x 2bpp images inside a single 4bpp image but because of that the compression is not really good and i required to use more advanced compression schemes.
Finally I think it would be better to do the 2bpp conversion in software and have plain 2bpp images to improve the compression ratio.
Bad Apple for NES uses a fairly transparent 1bpp scheme that
I've described, running at 15 fps, 64x60, 1bpp. A later version runs at 30 fps, 64x60, 1bpp, but uses a palette trick to overlay two frames of animation over each other (2bpp) to improve bandwidth to the PPU.
tepples wrote:
Bad Apple for NES uses a fairly transparent 1bpp scheme that
I've described, running at 15 fps, 64x60, 1bpp. A later version runs at 30 fps, 64x60, 1bpp, but uses a palette trick to overlay two frames of animation over each other (2bpp) to improve bandwidth to the PPU.
While the compression method is always interesting, the result : 64x60, 1bpp at 30 FPS is not, imo, that impressive even for a simple NES. I know the ROM size limitation is a big factor here but i believe we can do 128x112 and maintain 30 FPS. In that aspect the MD and SNES version are definitely more impressive.
The problem with 128x120-pixel video on the NES is that each 8x8 area (a tile) contains 16 pixels, so the possible pattern combinations are far too many (65536) to be available at all times (even with the MMC5, that can address 16384 tiles at a time). This means you either need to update CHR-RAM on the fly (which is slow as hell, so you can kiss those 30fps bye bye) or use tall pixels (8 per tile) and squeeze a 256x480-pixel area into 256x240 pixels.
Either way, another problem to solve is the lack of a back buffer. If updating patterns on the fly, a back buffer could be possible with an extra 8KB of CHR-RAM. If using the squeeze approach, 4 screen mirroring would solve the problem.
Updating patterns is more straightforward, but uploading 8KB worth of patterns takes 28 frames if you only use the regular vblank time. The other approach needs only 1920 bytes to be updated, but that would still take too long (about 7 frames, under normal circumstances).
To reach the desired 30fps, forced blanking will be necessary, cutting some of the picture at the top and bottom. In order to be able to change the picture every other frame, the resolution has to be reduced to 128x100, so the number of bytes to update becomes 1600, which can be copied in 2 extended vblanks.
Another issue is that squeezing the picture requires CPU intervention, so every 4 scanlines the CPU has to step in and change the scroll. Unfortunately this steals time that could otherwise be used for decompression. A mapper with IRQs would be necessary, because decompressing data with timed code would be insane, maybe even impossible.
I don't know enough the NES hardware and specially the different mapper capabilities but i guess using the 8 KB CH-RAM is the most flexible solution and should be enough to store tiles for the bad apple video sequence, you always have duplicate tiles.
Also you don't need to update all tiles at each frame and using 2bpp tiles to encode 1bpp data allow tiles update to be made at 15 FPS (4 frames per update). At lest for me 64x60 is really... blocky and does not look good :-/
tokumaru wrote:
Another issue is that squeezing the picture requires CPU intervention, so every 4 scanlines the CPU has to step in and change the scroll.
Every 8. Put a 4x2 pixel pattern in both the top half of each 8x8 pixel cell, then replicate it in the bottom half. Then in the middle of each row of tiles, you fire an IRQ and skip 8 lines.
So for a 128x88 pixel letterboxed scene:
lines 0-3 (screen lines 36-38): top half of nametable row 0
IRQ -> scroll to 12
lines 12-15 (screen lines 40-43): bottom half of nametable row 1
lines 16-19 (screen lines 44-47): top half of nametable row 2
IRQ -> scroll to 28
lines 28-31 (screen lines 48-51): bottom half of nametable row 3
lines 32-35 (screen lines 52-55): top half of nametable row 4
IRQ -> scroll to 44
lines 44-47 (screen lines 56-59): bottom half of nametable row 5
[...]
lines 336-339 (screen lines 204-207): top half of nametable row 42 (that is, row 12 of the bottom nametable)
IRQ -> scroll to 348
lines 348-351 (screen lines 208-211): bottom half of nametable row 43
This gives 262-176=86 lines of blanking, and at 14 bytes per line with a straightforward unrolled copy, you can fill 86*14 = 1204 bytes, which is just shy of the 32*44 = 1408 bytes of nametable data for 128x88. But decompression of that much data on a 1.8 MHz 6502 at 30 fps might be a pain.
Another technique is to find 256 "representative" 8x8 pixel tiles and use those to represent all the different tiles in the video. This doesn't require quite as much video memory bandwidth or IRQ hackery.
tepples wrote:
Every 8. Put a 4x2 pixel pattern in both the top half of each 8x8 pixel cell, then replicate it in the bottom half. Then in the middle of each row of tiles, you fire an IRQ and skip 8 lines.
Good idea!
Quote:
Another technique is to find 256 "representative" 8x8 pixel tiles and use those to represent all the different tiles in the video. This doesn't require quite as much video memory bandwidth or IRQ hackery.
Would it look good though? 256 tiles for the entire video might result in a lot of compression artifacts.
To improve this a little bit, you could have an alternate set on the other name table, so each frame of animation could select the set that better represents it.
tokumaru wrote:
Quote:
Another technique is to find 256 "representative" 8x8 pixel tiles and use those to represent all the different tiles in the video. This doesn't require quite as much video memory bandwidth or IRQ hackery.
Would it look good though? 256 tiles for the entire video might result in a lot of compression artifacts.
It's called vector quantization, and I imagine it'd still be a lot less noticeable than the artifact of reducing it to effing 64x60. But the biggest problem is still the 512K PRG ROM limit on both popular NES flash solutions.
tokumaru wrote:
The problem with 128x120-pixel video on the NES is that each 8x8 area (a tile) contains 16 pixels, so the possible pattern combinations are far too many (65536) to be available at all times (even with the MMC5, that can address 16384 tiles at a time).
Maybe I'm just being stupid right now, but with vertical and horizontal flipping, shouldn't this just about decrease the amount of tiles needed by 3/4s? If that's the case, the MMC5 would fit perfectly in that 65536 divided by 4 is 16384.
...Wait a minute. If you flip a solid black or white tile, it isn't going to make a difference. Never mind... (I don't know how much any of you would want to use the MMC5 anyway.)
tepples wrote:
It's called vector quantization
I know, but typically there's a new set of blocks every few frames... keeping the same set all the way through is what worries me. You could try to load a new set to the alternate pattern table progressively though, and have a keyframe every several frames. Or update a couple of tiles (that are not being used by the current image) every frame, in preparation for future images.
On the other hand, the Bad Apple video is the best candidate for something like this, since it's mostly filled white shapes over a black background (or vice-versa), so all you really have is edges.
Quote:
But the biggest problem is still the 512K PRG ROM limit on both popular NES flash solutions.
Maybe break it up into several 512KB ROMs?
Espozo wrote:
Maybe I'm just being stupid right now, but with vertical and horizontal flipping...
Besides the fact that flipping in each axis doesn't reduce the unique tile count by half, like you observed, the NES doesn't do background tile flipping natively, and neither does the MMC5.
MMC5 ExGrafix allows switching each tile's colors among four palettes, two of which could be set to black and white and white and black. This doubles possible tiles, as a single tile can be used for edges on both sides. Besides, you don't need all 65536 tiles; you just need the ones that are used in the picture.
tepples wrote:
MMC5 ExGrafix allows switching each tile's colors among four palettes, two of which could be set to black and white and white and black. This doubles possible tiles, as a single tile can be used for edges on both sides.
Another great idea. In fact, the second pattern doesn't even have to be the inversion of the first, since you can have 2 completely unrelated 1bpp images in a single 2bpp tile by using the following palettes:
Palette 0:
%00: black
%01: black
%10: white
%11: white
Palette 1:
%00: black
%01: white
%10: black
%11: white
Quote:
Besides, you don't need all 65536 tiles; you just need the ones that are used in the picture.
Yeah, even though there are 65536 possibilities, that doesn't mean the video uses them all.
I downloaded the original video, scaled it to the proposed resolution (128x88), converted it to B&W and exported all the frames, with the intent of writing a script to count how many of the 65536 possible patterns are actually used, but then I got lazy.
I also wanted to try quantizing the patterns down to 256 to have an idea of what that would look like, but this would be quite a lot of trouble.
I just wrote the script to count the patterns. If I did everything correctly, there are only 7,203 4x4-pixel patterns throughout the entire video. Considerably less than what the MMC5 can handle, so there's absolutely no need for palette tricks and whatnot. Next I want to sort the patterns by frequency and see if there's any chance of reducing that count to 256.
EDIT: I checked the frequencies of the patterns, and full black and full white are obviously at the top of the list, with 2,272,867 and 1,873,331 uses, respectively. The next entry in the list is used "only" 10,000 times. The 256th entry is used 156 times, and all entries after it are used a total of 53,557 times, so that's the amount of errors you'd have if you used only the first 256 patterns. At 6,566 frames, each with 704 blocks (6,566 * 704 = 4,622,464), 53,557 is only about 1,16% of the total, so it might actually be acceptable. Some errors might not even be easily noticeable if a similar enough substitute pattern can be found among the first 256.
BTW, sorry for hijacking this to talk about the NES, but I got carried away when the NES was mentioned. Split?
Well, I couldn't resist and I reduced the pattern count down to 256. Each pattern past 256 got mapped to one of the 256 most frequent ones (the one with least different pixels). I must say that the result is surprisingly good:
Attachment:
 apple-256-tiles.gif [ 1.83 MiB | Viewed 6430 times ]
apple-256-tiles.gif [ 1.83 MiB | Viewed 6430 times ]
You can see some stray pixels here and there near the edges, but it hardly makes any difference, the overall effect is still very fluid.
psycopathicteen wrote:
Isn't that a spam site? Before permitting downloading, it wants me to enter my email address, and to agree to receive advertisings from third party companies.
It's scant comfort, but at least they don't blacklist the temporary email providers I've found.
tokumaru wrote:
Well, I couldn't resist and I reduced the pattern count down to 256. Each pattern past 256 got mapped to one of the 256 most frequent ones (the one with least different pixels). I must say that the result is surprisingly good:
You can see some stray pixels here and there near the edges, but it hardly makes any difference, the overall effect is still very fluid.
Honestly that already looks much better than the low resolution version even if we have a lossy compression here (but not much).
Stef wrote:
Honestly that already looks much better than the low resolution version even if we have a lossy compression here (but not much).
I think it's great we don't even need any special effects for this, just a little extra blanking time (that easily fits in the letterbox area) and the rest of the time can be used for decompressing.
I even tried it with smaller tile sets just for fun, like only 32 for the whole video, and it still looked surprisingly decent. The still images were way blockier, but the smooth motion made up for that.
You know, what's stopping you from using the full resolution then? It may look even odder around the edges, but I imagine it would still look pretty decent.
Also, I forgot, are there any tricks with the palettes being used?
Espozo wrote:
You know, what's stopping you from using the full resolution then? It may look even odder around the edges, but I imagine it would still look pretty decent.
I was wondering about that myself. The reason I didn't try it is because my script was very poorly coded, and it uses a lot of RAM. It will need 4 times more RAM if I try the full resolution video, and I don't have that much free memory. To try this I'd have to rewrite the script, which I'm not sure I want to.
Quote:
Also, I forgot, are there any tricks with the palettes being used?
Not at all. We could easily have 2 sets of 256 patterns though, and select the best one for each 16x16-pixel area, and display the selected set by using the appropriate palette in each area.
That concept could be expanded to 2 more sets in the other pattern table, and use raster effects to select which pattern table is best for each scanline. That would overcomplicate the encoder though, and add the need for raster effects.
tokumaru wrote:
16x16-pixel area
Oh, yeah... I'm not exactly an expert when it comes to NES hardware. (I probably even have a better understanding of the Genesis.)
NEs tiles are 2bpp, but we only need 1bpp. This means you can store 2 1bpp patterns in each tile, and you can display one plane or the other by using special palettes:
This palette will show plane 0:
0 = black
1 = white
2 = black
3 = white
And this will show plane 1:
0 = black
1 = black
2 = white
3 = white
Mega Man 2 does this to animate the background in some stages, like Metal Man's.
The NES allows palettes to be applied to 16x16-pixel areas (unless you use the MMC5, of course) so that's the minimum area you can use to select one tile set (plane 0) or the other (plane 1).
BTW, I just figured out the logic to encode a full resolution version like this, so maybe I'll give it a try.
Well, I finished rewriting the script to handle 256x176-pixel images. Unfortunately, the results aren't so hot this time. Here are the first 2000 frames (I didn't do the whole thing because the new script is crazy slow):
Attachment:
 apple-nes-256x176.gif [ 1.38 MiB | Viewed 8917 times ]
apple-nes-256x176.gif [ 1.38 MiB | Viewed 8917 times ]
I'm using 2 sets of 256 patterns that can be selected for each 16x16 pixel area: the first set contains the most frequent 256 patterns, and the second contains the 64 most frequent patterns (repeated from the other set) followed by the 192 patterns that come after the first 256. I decided to repeat a certain amount of popular patterns hoping to increase the chances of the second set being selected (and it does get used, like, 1/4 of the time).
I honestly don't think this is an improvement over the 128x88-pixel version. What good is it to have more resolution if the fine details are all mangled? And this is just the first 2000 frames... I imagine it could get a little worse if all frames were processed, since that would mean more images being represented by the same amount of blocks. Things didn't change much when I went from 1000 frames to 2000 though, so who knows...
Still, this was an interesting exercise, and I think it's fun to see the program trying to recreate the original images from such a limited amount of blocks.
OK, now I'm done with this Bad Apple business. No more distractions for me!
Indeed this time it looks a bit too blocky and i also prefer the lower resolution. There is a 4 MB version on Megadrive which use a lossy compression and look a bit blocky as well (not that much but still too much imo). I would really like to fit the MD version in 4MB instead of 8MB (and so having it working on almost all flash carts) but i don't know if that is possible.
I realized that since there are still 2 free palettes, that these could be used to display more variations of the patterns that are already loaded. Unfortunately, it's not possible to simply swap black and white, since color 0 must always be black... but there are still a total of 8 possible palette configurations:
black, black, black, black (useless)
black, white, black, black (plane 0 - plane 1)
black, black, white, black (plane 1 - plane 0)
black, white, white, black (plane 0 XOR plane 1)
black, black, black, white (intersection between plane 0 and plane 1)
black, white, black, white (plane 0 only, already in use)
black, black, white, white (plane 1 only, already in use)
black, white, white, white (plane 0 OR plane 1)
Maybe two of these operations will result in patterns that are similar to the ones that are actually used in the video, and each 16x16-pixel area will have more options of patterns to choose from. For this to be really useful though, a more complicated analysis of the patterns should be made so that they are arranged in the optimal order in each plane to generate the most useful combinations, but that's way too hardcore for me. It would even make much more sense to have the repeated patterns in different positions, so they don't generate useless combinations. Right now I just have them arranged by frequency (most common patterns come first).
Did you consider the effect of allowing minor scrolling? It'd let you move the attribute and pattern grids. Of course, that would mean 256x the checking per-frame to encode...though you wouldn't need to do that for pure-black or pure-white areas, just those near edges. If you don't want to check extra pattern options, you could just see if one of the other attribute alignments (+8,0), (0,+8), (+8,+8) would give you better options overall...or in any given frame.
Might let you get a better fit into 256-tiles-alloted.
[And separately, 8x8-tile attributes are relatively cheap, mapper-wise...if you don't mind going beyond traditional.]
Interesting ideas. Testing all of these rotations would indeed be slow as hell with the script I have now (except for the different 8x8 alignments).
I'm definitely not trying any of this now though... Like I said, I can't afford any more distractions.
Checking for just-pans (or near-pans) that would convert better to scrolling, like the sword, or Marisa bobbing in flight [scroll-split?], might also get you some pattern space- but one can pretty easily guide where a program should check for that.
Had you considered using the "just plane 1"/"just plane 2" trick (or an upgraded method for SNES, having more bitdepth) to get multiple frames for one update in your tight spots(Flandre), where you'd just have to switch the palette entry?
Wait a minute, if we're doing split screen scrolling and stuff, why not just make the tilemap 256 x 512 and have it to where you're essentially using 8x4 tiles? Even lines would use the top half of the tiles, and odd lines would use the bottom half.
Espozo wrote:
Wait a minute, if we're doing split screen scrolling and stuff, why not just make the tilemap 256 x 512 and have it to where you're essentially using 8x4 tiles? Even lines would use the top half of the tiles, and odd lines would use the bottom half.
Moving the tilemap up 4 pixels on every 4th scanline would be an interesting solution.
Just thought of another improvement to the NES version: before encoding, separate the frames into 2 groups, based on similarity. Then, encode each group separately, resulting in 2 pattern tables worth of monochrome patterns, so each frame gets to choose the pattern table that will best represent it. That will double the amount of patterns for the entire video, although I'm sure there will be quite a few duplicates.
tepples wrote:
This gives 262-176=86 lines of blanking, and at 14 bytes per line with a straightforward unrolled copy, you can fill 86*14 = 1204 bytes, which is just shy of the 32*44 = 1408 bytes of nametable data for 128x88. But decompression of that much data on a 1.8 MHz 6502 at 30 fps might be a pain.
How about using 8K WRAM to hold 1410 instruction pairs of the form "LDA #xx / STA $20xx", storing five groups of 51 bytes of data for the LDA in each page of ROM, interleaved (so an unrolled sequence of 51 consecutive "ldy #0 [or 5, 10, 15...] / lda (src),y / sta (dest),y" will copy 51 bytes), and then use a separately-stored sequence of bytes to indicate which sta instructions need to store to $2006 instead of $2007. For the scenario where all 1410 stores are needed, the time during vblank would be 8260 cycles and the time to prepare all the stores would be 18330 cycles. In the cases where stores are going to be patched to hit $2006 instead of $2007, some time would be required to do that patching before running the code in WRAM and then undo it afterward, but since fewer loads would need to be prepped, the time spent patching would still be a net "win".
If replacing every sequence of three or more bytes that match a previous frame with the two byte address of the next sequence of bytes requiring updates would be adequate to meet compression requirements, I don't think there would be any problem running the uncompressor in real time if audio doesn't gobble too much CPU.
tokumaru wrote:
Well, I couldn't resist and I reduced the pattern count down to 256. Each pattern past 256 got mapped to one of the 256 most frequent ones (the one with least different pixels). I must say that the result is surprisingly good:
Have you tried porting that to the NES? I'd say it looks pretty good.
supercat wrote:
Have you tried porting that to the NES? I'd say it looks pretty good.
Nope, I just wrote a script in PHP to encode the tiles (don't know if I still have it) and made a GIF of the result.
I though it looked cool too... the fluidity really compensated for the incorrect pixels, IMO. Making a demo should be trivial, all the work would be in selecting a compression scheme that worked well on the name table data. Just a little bit of forced blanking should be enough to guarantee a frame rate of 30.
tokumaru wrote:
supercat wrote:
Have you tried porting that to the NES? I'd say it looks pretty good.
Nope, I just wrote a script in PHP to encode the tiles (don't know if I still have it) and made a GIF of the result.
I though it looked cool too... the fluidity really compensated for the incorrect pixels, IMO. Making a demo should be trivial, all the work would be in selecting a compression scheme that worked well on the name table data. Just a little bit of forced blanking should be enough to guarantee a frame rate of 30.
What do you think of the idea of using cartridge WRAM to hold a sequence of "lda #xx / sta $200x" instructions? If you're using 32x24 normal-height tiles (as opposed to using half-height tiles to enable arbitrary half-resolution pixel patterns), a worst-case update would be 4620 cycles, which is only about 40 scan lines, and significant compression could be achieved by simply evaluating the differences between frames, identifying what combination of vertical and horizontal updates could best achieve them, and arranging to have the store sequence contain mostly stores to $2007, but a few pairs of stores to $2006 and possibly one store to $2000 (to switch from horizontal to vertical updates). If one imposed a limit of 303 PPU writes per 60Hz frame, it may be possible to get by without cartridge WRAM or extended vblank. I don't know how many frames would need more than 303 tiles to change at once, but I'd guess many of those could be handled if one set the four palettes to black/white, black/black, white/white, and white/black and then used palette updates to switch set the attributes of groups of 16 tiles at once.
Bad Apple's popularity may have passed, but I think the existing demo falls far short of what the NES should be able to achieve.
supercat wrote:
What do you think of the idea of using cartridge WRAM to hold a sequence of "lda #xx / sta $200x" instructions?
I think it's useful in other cases, but not really needed here. Since the picture is only 24 tiles high, as opposed to the full 30, there are 48 scanlines with no picture that we can blank and use for VRAM updates, plus the regular 20 of vblank. Updating all 32x24 tiles plus the 64 attribute bytes at the "slow" rate of 8 cycles per byte would take less than 60 scanlines, so you could even do 60fps video if you wanted. VRAM transfers are not the bottleneck here.
The real bottleneck IMO is PRG-ROM space, since common Nintendo mappers only go as high as 512KB. You'd need a fairly advanced compression scheme to make efficient use of the available space, meaning that the decompression process could end up being too heavy for the CPU. How many frames does the entire animation have? We need to divide the available ROM space by that in order to find out the average bitrate that the compression scheme must achieve.
It looks like the video is 3 minutes and 39 seconds long, or 219 seconds. Times 30 frames per second, that's a total of 6570 frames. If the total PRG-ROM size is 512KB, the average data rate would have to be 524288 / 6570 = 79.8 bytes per frame. Yeah, getting 832 bytes down to 80 sounds like a real challenge. We'd need really good temporal compression, in addition to spatial compression. And there's also the program and the music stealing some of that space. Maybe CHR-ROM could be used for some extra storage?
https://www.filehosting.org/file/detail ... 0Apple.zipWorks perfectly in BSNES. I got it working in SNES9x again, you just have to hit reset in SNES9x to get it to work correctly for some reason. I still can't figure out why it doesn't work in Higan.
EDIT: Wait, it works in later versions of Higan.
Here's the best version:
http://www.mediafire.com/file/nkqvxq2tm ... e.zip/file
What's new? It's been a while since I saw one of these... I believe there was some issue with getting the sound to work on real hardware; has that been solved?
It works on every emulator now, so chances are it works on real hardware too.
I assume this photo of one of the frames being displayed properly is intended to imply that the audio works the whole way through too...
...
Performance looks good, at least in Snes9X (which has hotkey frame advance). Several lag frames with Flandre, but I didn't notice any in the other traditional trouble spots (the tree and the musical poltergeists).
I believe you had a scheme in mind where the tilemap decompression happened during VBlank, thus opening the road to possible use of HDMA during the frame. (Or does the tile decompressor use DMA too?) Have you had a chance to look at that?
Yes, audio plays on my 1/1/1. But I'm not intimately familiar enough with the original to tell with certainty whether this version keeps perfect sync.
Yeah, it's not going to keep perfect sync. We've had this issue before.
1) that TV of yours looks like it's probably got a bit of internal lag,
2) the nominal video and audio clocks aren't exactly 60 and 32000 Hz,
3) on real hardware, the video/audio sync isn't reliable anyway due to the APU's use of an independent ceramic oscillator,
4) the source video doesn't seem to have had perfect sync in the first place.
With emulators it's even worse.
Anyway, the proof of principle is what's important. From that perspective, as long as the audio plays cleanly on real hardware, we're good. Audio glitches are much more noticeable than lag frames, so it's easier to be confident in a clean playback. Once it's running with zero lag frames and 24 kHz stereo, we can badger him about synchronization...
Much of the song (prior to the gear change at the end) appears to be played twice. Can that be exploited to increase the sample rate or add a reduced-frequency side (L-R) channel for mid-side stereo?
Maybe. If chunks of it are effectively identical to each other, you could reuse the data. It could be complicated to line up the BRR blocks accurately enough to make it work seamlessly... and you'd have to make sure they were really identical, lest you get caught cheating by someone who knows the song better...
I don't know how much free ROM there is in the current version; I had the impression it was fairly tight. But it's only 64 Mbits, and a 95 Mbit ROM would still work on all the flash carts that can handle 64. Assuming the video decoder can avoid using DMA during active display, and that stable high-bandwidth HDMA streaming can be made to work, there's enough room in a 95 Mbit map for 24 kHz stereo, or 32/16 kHz mid-side, with no weird tricks. Using your proposed scheme, if enough of the music data turns out to be reusable, 32 kHz stereo might even work.
What bugs me about this idea is that it seems to have the same issue my trick with highpassed samples does, which is that it's content-specific and requires manual work; thus it doesn't really qualify as a codec...
The
mp3 PlusV codec (see
discussion) attempted to represent everything above 8 kHz as noise shaped by a spectrum envelope. This was a simplified counterpart to mp3PRO, which used spectral band replication and some per-frame metadata to copy low frequencies to high. Perhaps some techniques from PlusV could help turn "highpassed samples" into an actual codec.
So... an automatically generated timestamped list of 8-tap FIR filters (or indices into a table thereof) and volumes/envelopes to use on a noise channel, using an EDL of 0?
In any case, you'd get monaural high frequencies, so if you've got extra bandwidth you might be better off with 32/16 mid-side. On the other hand, this might fit in 64 Mbits and might not require radical changes to the audio engine. And on the other other hand, maybe you could use this together with 32/16 mid-side to generate pseudo-32/32 mid-side that fits in 95 Mbits...
Can a filter that short provide the necessary steepness and complexity to make this technique sound decent? I don't like the idea of automatically-generated prefiltered noise loops; that could sound pretty terrible and/or require an inordinate amount of intelligence from the codec, especially given the strict bandwidth and audio RAM limits. But perhaps one highpassed noise loop could be justified more easily; that way the onboard filter wouldn't need the steepness to stay out of the sampled music's range without leaving a big hole in the spectrum. (A modest highpass component might still be a good idea; BRR tends to add noise back into the low end regardless of how steep the prefilter is.)
More importantly, it seems to be impossible to guarantee glitch-free filter updates for dynamic spectrum shaping. The fastest method I can think of would take two samples at 32 kHz between the first and last filter coefficient writes, which means a couple of sample points would go through a partially updated filter every time. Since it's noise, maybe it wouldn't sound too bad... and some of Ocean's soundtracks seem to have used a similar technique; I don't know if they used the whole filter, but Dean Evans said some of their fancy techniques could produce pops at times...
...
Perhaps I've dismissed the idea of automated generation of multiple shaped-noise samples a bit too quickly. You could have a rolling cache of them in ARAM, reloading older ones as needed if they've dropped off the back and been overwritten. With HDMA streaming, the hit to video decoding compute time could be minimal... as long as care is taken to keep the total bandwidth low, since of course if you go too nuts you could end up with a string of unique samples all crossfading into each other, which would take more bandwidth (and data) just for fake sizzle than you'd need for an entire 32 kHz track...
If the FIR filter method reliably sounds okay, it might be more elegant... Either of these methods would also probably ease timing requirements vs. my highpassed samples idea, which needs very precise trigger points (all these methods likely need APU-side timing because the potential drift rate vs. the main clock is just too high, but it helps if the effect doesn't sound stupid because it was supposed to trigger in the middle of a 32-line HDMA burst and had to wait)...